如何從學術文獻中挖掘規律,甚至溯源文獻的研究方法等?來自天津大學、之江實驗室和中科院自動化所的研究者借鑒生化領域中分子標記示蹤的思想,對文獻正文中反映研究過程的信息進行示蹤,挖掘出了方法的演化規律等更多有價值的信息。
將學術文獻中蘊含的規律挖掘出來是非常有意義的。借鑒生化領域中分子標記示蹤的思想,本文將 AI 文獻中的方法、數據集和指標這三種同粒度的命名實體作為 AI 標記,對文獻正文中反映研究過程的信息進行示蹤,進而為文獻挖掘分析開拓新視角,并挖掘更多有價值的學術信息。
首先,本文利用實體抽取模型抽取大規模 AI 文獻中的 AI 標記。其次,溯源有效 AI 標記對應的原始文獻,基于溯源結果進行統計分析和傳播分析。最后,利用 AI 標記的共現關系實現聚類,得到方法簇和研究場景簇,并挖掘方法簇內的演化規律以及不同研究場景簇之間的影響關系。
上述基于 AI 標記的挖掘可以得到很多有意義的發現。例如,隨著時間的發展,有效方法在不同數據集上的傳播速度越來越快;中國近年來提出的有效方法對其他國家的影響力越來越大,而法國恰好相反;顯著性檢測這種經典計算機視覺研究場景最不容易受到其他研究場景的影響。
1 介紹 & 相關工作
對學術文獻的探索能夠幫助科研人員快速和準確地了解領域發展狀況以及發展趨勢。目前大多數的文獻研究嚴重依賴論文的元數據,包括作者、關鍵詞、引用等。Sahu 等人通過對文獻作者數量的分析來探索其對文獻質量的影響[19]。Wang 等人通過對引用數量的統計,發布 AI 領域學者高引排行榜 。Yan 等人使用引用數量來估計未來的文獻引用[26]。Li 等人使用從文獻元數據衍生的知識圖譜來比較嵌入空間中的實體相似性(論文、作者和期刊)[12]。Tang 等人基于關鍵詞和作者的國家研究 AI 領域的發展趨勢[27]。此外,還有大量基于作者、關鍵詞、引用等對文獻進行分析的研究[4, 13, 14, 20, 24]。
由于元數據涉及到的語義內容有限,一些學者對文獻的摘要進行分析。摘要是對文獻內容的高度概括,主題模型是主要的分析工具[5, 6, 18, 21, 22, 31]。Iqbal 等人利用 Latent Dirichlet Allocation (LDA) 來探索 COMST 和 TON 中的重要主題[8]。Tang 等人利用 Author-Conference-Topic 模型構建學術社交網絡[23]。此外,Tang 等人分析發現當前熱點研究話題 TOP10 為 Neural Network、Convolutional Neural Network、Machine Learning 等 。但是,基于主題模型對摘要進行主題分析存在主題粒度不一致的問題。例如 Tang 等人發現的當前熱點研究話題 top10 里面,Neural Network、Convolutional Neural Network、Machine Learning 三個話題的粒度完全不一致。
摘要中蘊含的主要是結論性信息,缺少反映研究過程的信息。文獻正文中包含了研究的具體過程,但目前還基本未見有對文獻正文的研究。其中一個主要原因是,論文正文通常包含幾千個單詞。在遠超摘要長度的正文上,利用現有主題模型技術進行分析,可能會導致正文中與主題相關性低的非主題單詞也會被作為主題單詞。
我們注意到,生物領域中常用分子標記法來追蹤反應過程中物質和細胞的變化,從而獲取反應特征和規律[29, 30]。受此啟發,我們發現在文獻的特征與規律挖掘中,方法、數據集、指標能夠起到和分子標記物相同的作用。我們將 AI 文獻中這三種同粒度的命名實體作為 AI 標記,利用 AI 標記來對正文中反映研究過程的信息進行示蹤。圖 1 描述了 AI 標記和分子標記的相似性。基于 AI 標記的挖掘補充了常規的基于元數據和基于摘要的挖掘。
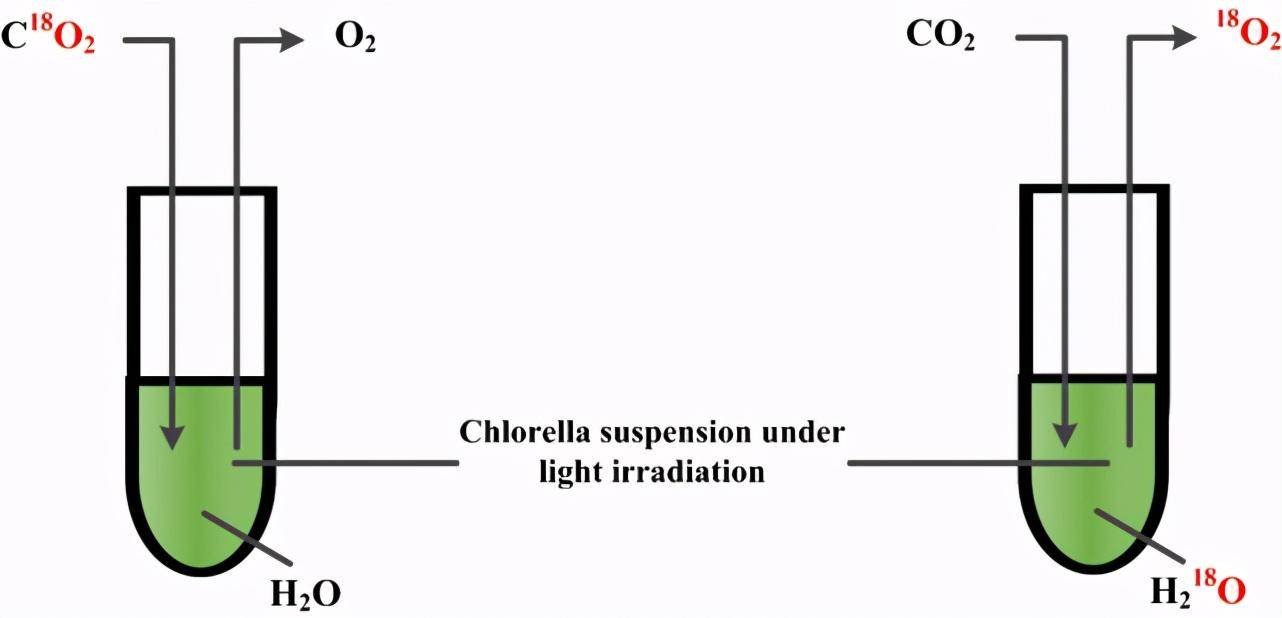
(a) Samuel Ruben 和 Martin Kamen 使用氧同位素 18O 分別標記 H2O 和 CO2,跟蹤光合作用中的 O2 的來源。
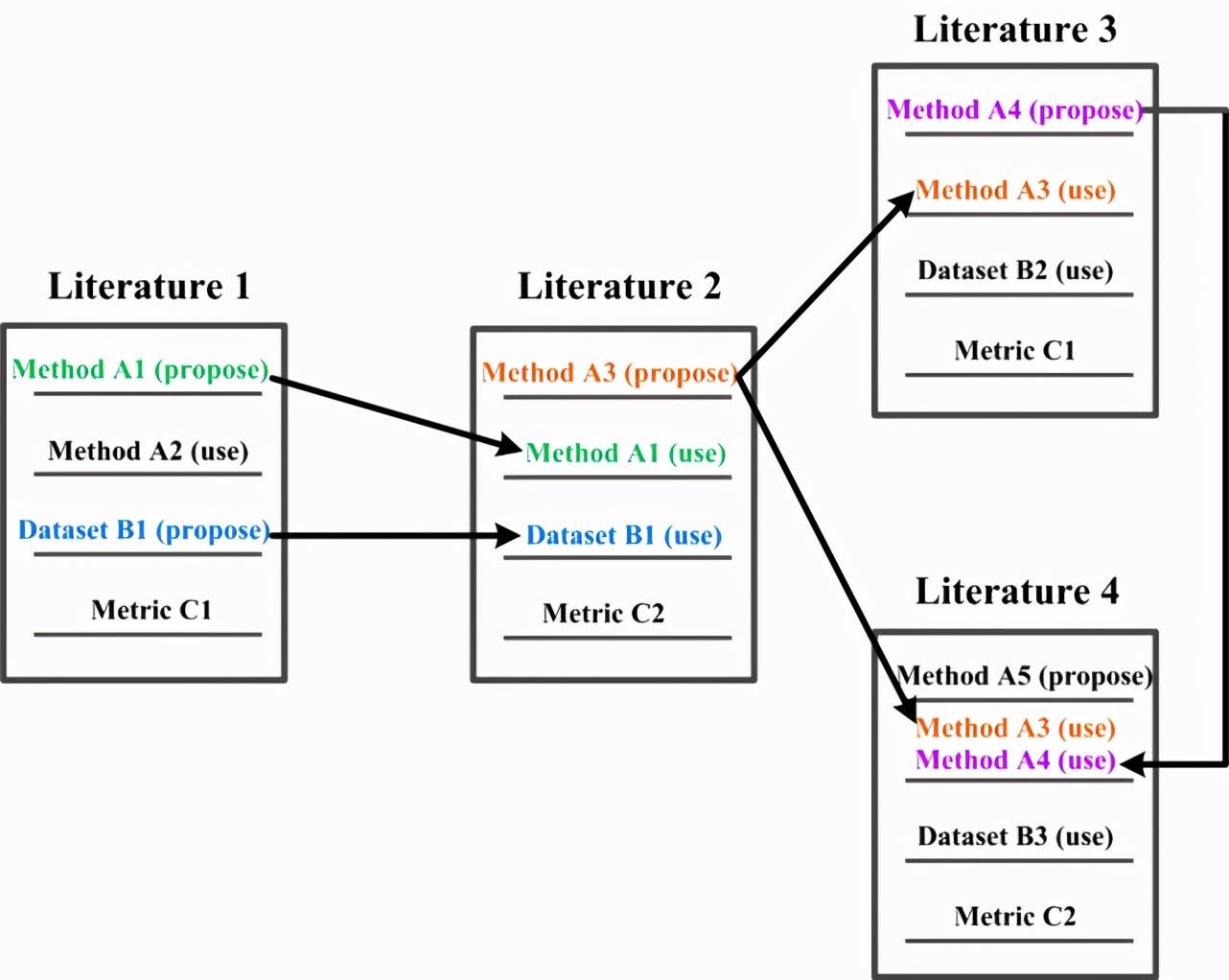
(b) 當 AI 標記被其他文獻提出或引用時,就形成了特定研究過程中的蹤跡。因此,AI 標記在挖掘文獻的特征和規律性方面可以起到與分子標記相同的作用。
Figure 1:AI 標記和分子標記類比圖
在我們的研究中,首先利用實體抽取模型對大規模 AI 文獻中的 AI 標記進行抽取,并對有效 AI 標記(方法和數據集)進行統計分析。其次,我們對抽取的有效方法和數據集進行原始文獻的溯源,對原始文獻進行統計分析,并且研究了有效方法在數據集上和在國家之間的傳播規律。最后,根據方法和研究場景共現關系來實現對方法和研究場景的聚類,得到方法簇和研究場景簇。基于方法簇及關聯數據集繪制路徑圖,研究同類方法的演化關系,基于研究場景簇來分析方法對研究場景以及研究場景之間的影響關系。
通過基于 AI 標記的 AI 文獻挖掘,我們可以得到如下主要發現與結論:
我們從有效方法和數據集的新角度,通過對 AI 標記進行統計分析,獲得了反映 AI 領域年度發展情況的重要信息。例如,2017 年無人駕駛領域的經典數據集 KITTI 躋身于 top10 數據集,說明無人駕駛是 2017 年的熱門研究主題;
在對 AI 標記進行溯源得到的原始文獻的統計分析層面,我們發現新加坡、以色列、瑞士提出的有效方法數量相對較多;從有效方法在數據集上的應用情況來看,隨著時間的發展,有效方法應用在不同數據集上的速度越來越快;從有效方法在國家間的傳播程度來看,中國提出的有效方法對其他國家的影響力越來越大,而法國恰好相反;
基于方法簇和數據集信息,我們構建了方法路徑圖,能夠展示同一方法簇內各個方法的時間發展史及數據集應用情況;對于場景簇,我們發現與顯著性檢測相關的經典計算機視覺研究場景最不容易受到其他研究場景的影響。
2 數據
在我們文獻挖掘的研究過程中,需要用到大量的文獻數據,因此,本節首先介紹了我們收集的文獻數據。此外,在研究過程中,我們需要用到兩個機器學習模型。因此,本節對這兩個模型的訓練數據也分別進行了介紹。
2.1 收集的文獻數據
我們使用中國計算機學會(CCF) 等級(Tier-A、Tier-B 和 Tier-C)中的 AI 期刊和會議列表,收集了 2005 年至 2019 年出版的 122,446 篇論文。用 GROBID 將 PDF 格式的論文轉換為 XML 格式,從 XML 格式論文中提取標題、國家、機構和參考文獻等信息。為了便于閱讀,我們將收集到的這些數據稱為 CCF corpus。
2.2 章節分類的訓練數據
通常,一篇 AI 文獻的正文包括引言、方法介紹、實驗章節、結論四個部分。本文利用章節分類策略將 AI 文獻的正文按上述四部分進行分類。
我們隨機選取 2000 篇 CCF corpus 中的文獻,并招募 10 名 AI 領域研究生標注這 2000 篇論文中的 63110 個段落。我們稱該數據為 TCCdata。TCCdata 用來構建章節分類中的 BiLSTM 分類器[3]。TCCdata 中每類章節的數量以及每類章節包含的段落數量如表 1 所示。
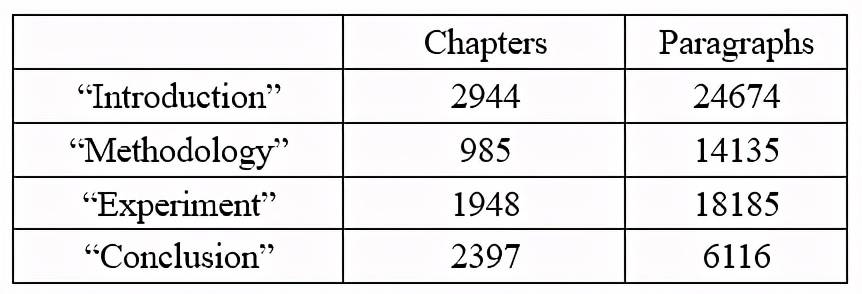
Table 1:TCCdata 中章節和段落的數量
2.3 AI 標記抽取的訓練數據
為了訓練 AI 標記抽取模型,我們隨機選取 1000 篇 CCF corpus 中的文獻。將文獻正文中方法章節和實驗章節的內容按標點符號切分成句子,并招募 10 名 AI 領域研究生對這些句子進行標注。我們采用 BIO 標注策略標注方法、數據集、指標這三種實體,利用機器之心編譯好的方法、數據集、指標作為標注參考。最后我們得到 10410 個句子,稱之為 TMEdata。
在構建 AI 標記抽取模型時,我們將 TMEdata 按照 7.5:1.5:1 的比例劃分成訓練集、驗證集和測試集。訓練集、驗證集和測試集中包含的三種 AI 標記的數量如表 2 所示。
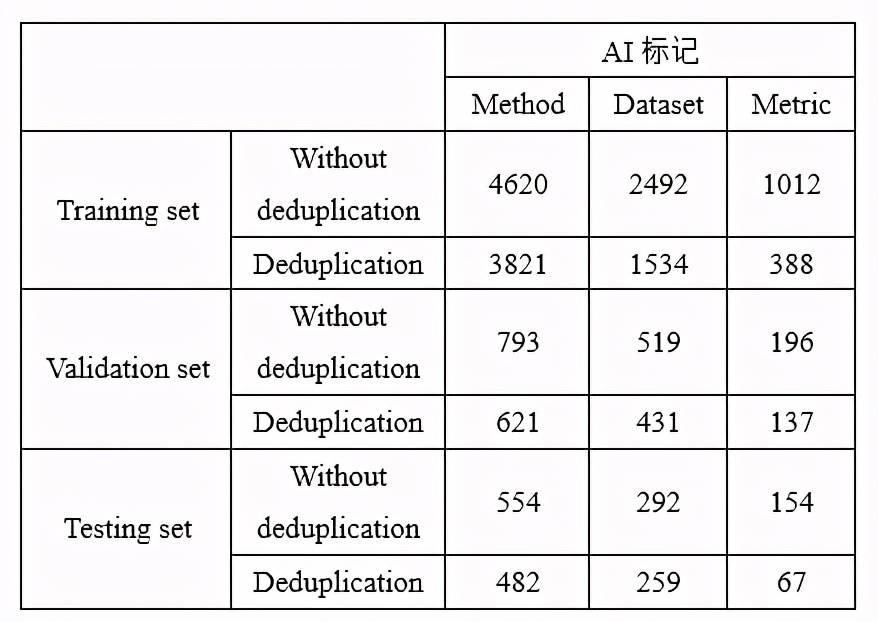
Table 2:TMEdata 中 AI 標記的數量
3 方法
本節介紹本項研究所涉及的具體方法,包括章節分類、AI 標記的抽取與歸一、AI 標記原始文獻的溯源、方法和研究場景的聚類、方法簇內路徑圖的生成以及研究場景簇的影響程度。
3.1 章節分類
在一篇 AI 文獻正文中,位于方法章節和實驗章節的 AI 標記對該篇文獻起著實質性作用,因此我們只對 AI 文獻正文中方法章節和實驗章節的 AI 標記進行抽取。但是,由于 AI 文獻正文結構的多樣性,難以用簡單的規則策略對 AI 文獻正文章節進行較為準確的分類。因此,本文提出了BiLSTM 分類器和規則相融合的章節分類策略。
3.1.1 提出的分類策略
章節分類的整體流程如圖 2 所示。對于一篇 AI 文獻的正文內容,我們首先利用規則匹配(關鍵詞和順序)對正文章節進行標注。對于匹配到的章節,則輸出章節標簽。對于未匹配到的章節,則將章節下的段落輸入到基于 TCCdata 訓練的 paragraph-level BiLSTM 分類器進行預測。接下來對相同章節標題下的段落預測結果進行投票,將出現次數最多的標簽作為該章節類別。最后,將基于規則匹配得到的章節標簽與基于投票得到的章節標簽結合,得到整個正文的章節標簽。
我們采取了常規的 one layer BiLSTM 架構。其中最大句子長度選取為 200,詞向量的維度選取為 200,hidden 維度選取為 256,batchsize 選取為 64。采用交叉熵作為損失函數,TCCdata 作為訓練數據。
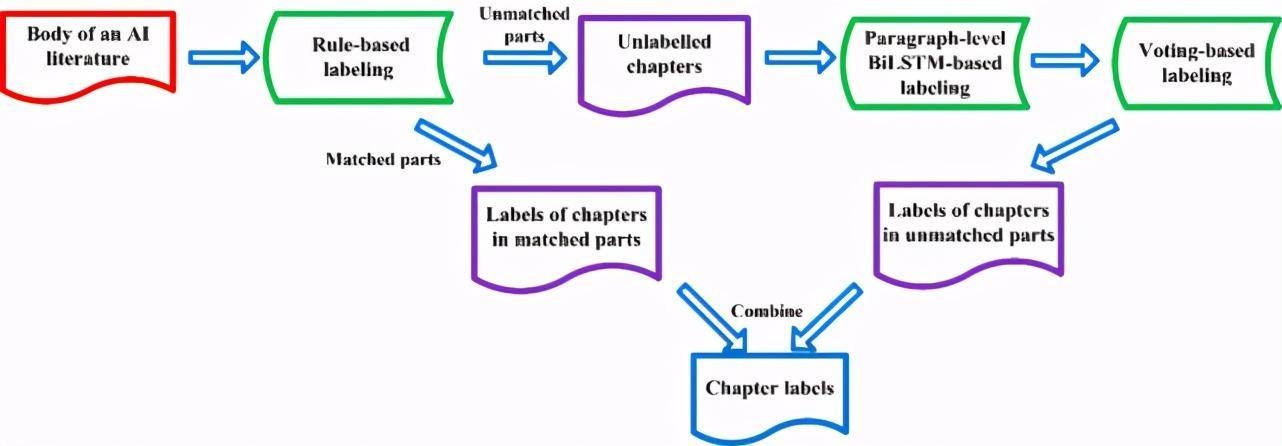
Figure 2:章節分類整體流程
3.1.2 評估結果
我們將 TCCdata 以 8:1:1 的比例劃分成訓練集、驗證集、測試集。在測試集上,我們對規則匹配、paragraph-level BiLSTM、規則匹配與 paragraph-level BiLSTM 結合這三種章節分類方式分別進行了評估。結果表明,僅利用規則匹配,準確率為 0.793。僅利用基于 TCCdata 訓練的 paragraph-level BiLSTM,準確率為 0.792。將規則匹配與基于 TCCdata 訓練的 paragraph-level BiLSTM 結合后,準確率達到了 0.928。
3.2 AI 標記的抽取與歸一
AI 標記的抽取與歸一具有很大的挑戰。由于每年都會涌現出大量 AI 文獻,新的 AI 標記數量不斷增加,形式也多種多樣,一些常見詞可能也會被當作數據集。例如 DROP 在 2019 年發表的 [2] 中被當成數據集。AI 標記的命名沒有特定的規范。此外,一些 AI 標記存在歧義的問題。例如 CNN,既可以表示 Cable News Network 數據集,又可以表示 Convolutional Neural Networks 方法。比如 LDA,既可以表示 Latent Dirichlet Allocation 方法,又可以表示 Linear Discriminant Analysis 方法。
3.2.1 AI 標記抽取模型
AI 標記抽取是一個典型的命名實體識別問題。本文采用的 AI 標記抽取模型基于目前經典的 CNN+BiLSTM+CRF 框架[15],并作了小的改進,如圖 3 所示。
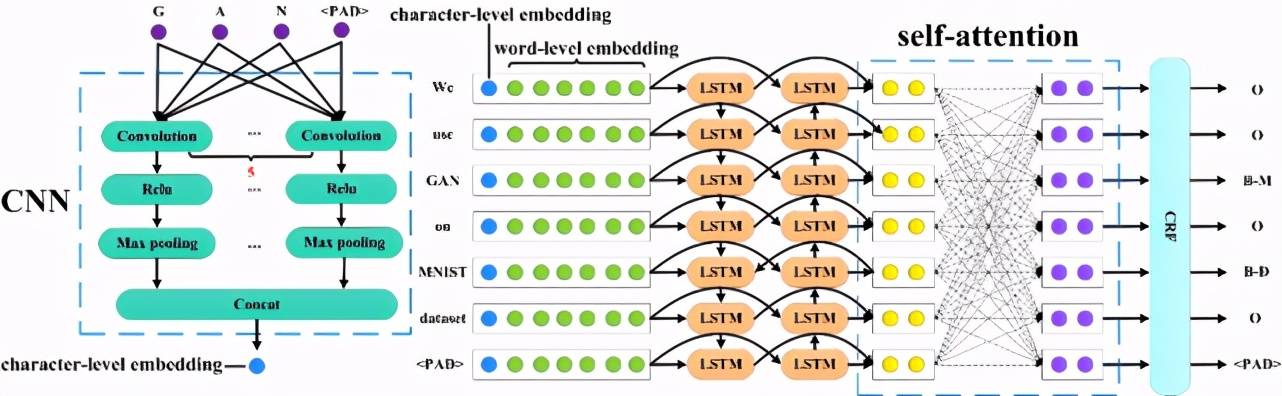
Figure 3:AI 標記抽取模型結構
對于一個輸入句子 ,其中 w_i 表示第 i 個單詞。首先將每個單詞切分成字符級,通過 CNN 網絡獲取到每個單詞的 character-level embedding。然后經過 Glove embedding[17] 模塊獲取到每個單詞的 word-level embedding。將句子中每個單詞的 character-level embedding 與每個單詞的 word-level embedding 拼接,然后送入到 Bi-LSTM。使用 self-attention[25] 計算每個單詞與其他所有單詞之間的關聯。最后,將通過 self-attention 獲取到的隱向量送入 CRF[10],得到每個單詞的標簽序列 y。y∈,分別對應方法、數據集、指標和其他。
3.2.2 實驗設置
模型參數設置如下。最大句子長度選取為 100,最大單詞長度選取為 50,batchsize 選取為 16。字符級 CNN 網絡使用 5 個并列的 3D 卷積 - 激活 - 最大池化,5 次卷積中每次分別用 10 個 1*1*50,1*2*50,1*3*50,1*4*50,1*5*50 的 3 維卷積核,激活函數均使用 ReLU。最后將 5 次得到的結果進行拼接,得到每個單詞 50 維字符級詞向量。Bi-LSTM 選用一層,hidden 維度選為 200,self-attention 的 hidden 維度選為 400。
3.2.3 評估結果
利用原始樣本與其對應的小寫化后的樣本對模型進行訓練。在測試時,我們分別對測試樣本(1040 個句子)及其對應的 1040 個小寫化后的樣本進行測試。AI 標記抽取模型的評估結果如表 3 所示。
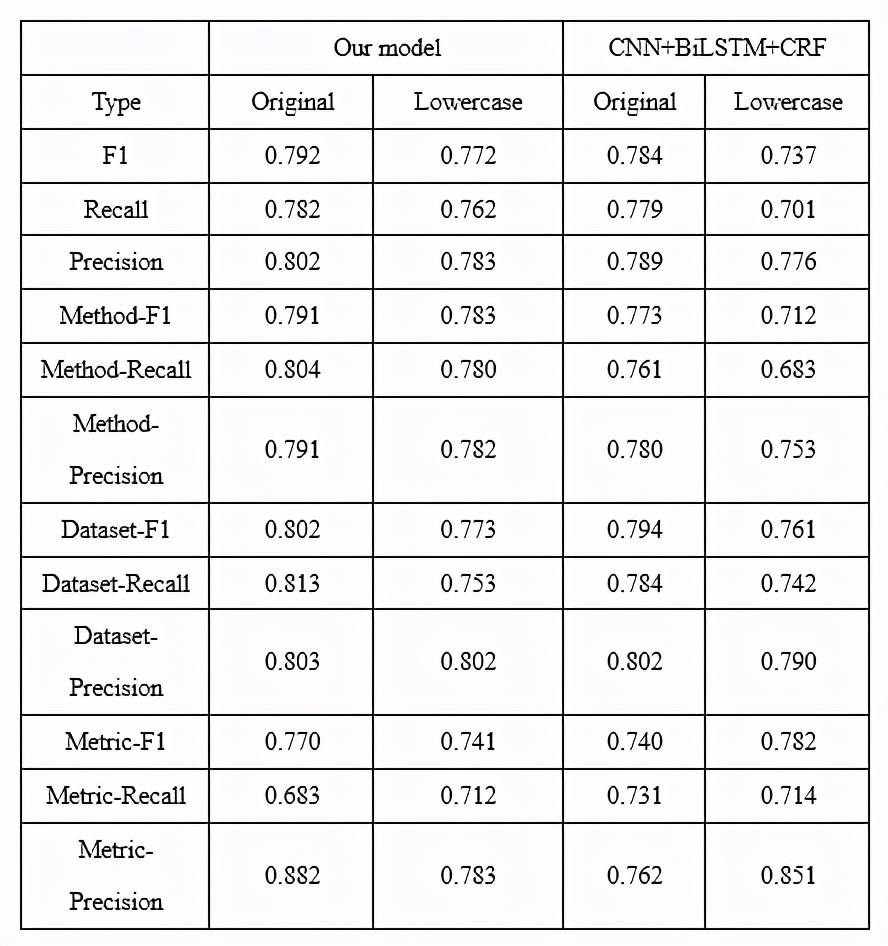
Table 3:AI 標記抽取模型評估結果
由表 3 可看出,相比于傳統的 CNN+BiLSTM+CRF 模型,我們的模型無論是對于 AI 標記的整體識別,還是各個 AI 標記的單獨識別,在 F1、Recall、precision 三個指標上效果均有所提高。此外,結合黑白名單等規則進行優化后,我們模型的 F1 為 0.864,Recall 為 0.876,Precision 為 0.853。
3.2.4 AI 標記歸一
對于一些有多種表示形式的 AI 標記,我們制定了一系列的規則策略進行歸一化。例如,對于方法「Long Short-Term Memory」,我們將「LSTM」、「LSTM-based」、「Long Short-Term Memory」等歸一化成「LSTM (Long Short-Term Memory)」。對于指標「accuracy」,我們將「mean accuracy」、「predictive accuracy」等包含「accuracy」的指標都歸一化成「accuracy」。詳細歸一化策略參見附錄 A。對于出現的一些一詞多義的情況,考慮到很多 AI 標記能夠根據實體類別進行區分,且同一類型的一詞多義出現概率很小,我們不對這種情況專門進行處理。
3.3 AI 標記原始論文溯源
要想得到一個方法或數據集從提出開始逐漸被其他文獻引用的研究蹤跡,首先需要追溯到方法和數據集的原始文獻。我們將追溯到的方法和數據集原始文獻稱為「原始論文」。我們只對明確出現在后續文獻的方法或者實驗章節的方法或數據集進行追溯。
3.3.1 溯源方法
考慮到在一篇文獻中,方法或數據集在被引用時,后面經常會附有其對應的原始論文。因此,在我們提出的溯源方法中,對于每個 AI 標記,我們首先找出引用該 AI 標記的文獻集合。對于文獻集合中的每篇文獻,查找該 AI 標記出現的句子集合。對于每個句子,查看該 AI 標記后面的一個位置或者兩個位置是否有參考文獻,將有參考文獻的信息記錄下來。最后,將每個 AI 標記對應的引用數量最多的文獻作為其原始文獻。
3.3.2 評估結果
利用本文的溯源方法,我們追溯到了 CCF corpus 中提出的被明確引用次數大于 1 的方法的原始文獻 4105 篇,方法 5118 個。追溯到 CCF corpus 中提出的被明確引用次數大于 1 的數據集的原始文獻 949 篇,數據集 1265 個。
我們隨機抽取得到的結果中被明確引用次數為 5、4、3、2 的方法各 200 個,被明確引用次數為 5、4、3、2 的數據集各 100 個。對這 800 個方法和 400 個數據集對應的原始文獻結果進行人工評估,評估結果見表 4。結果準確率都超過了 90%。
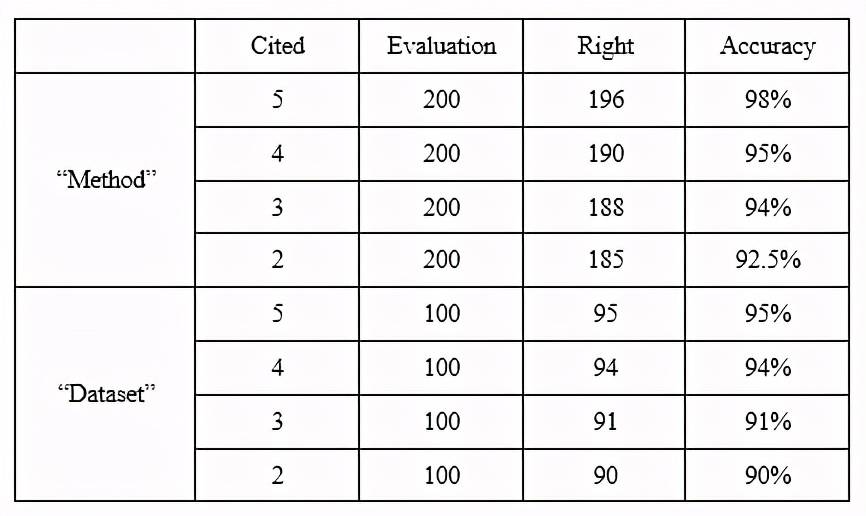
Table 4:溯源方法的評估結果
3.4 方法和研究場景的聚類
單獨的數據集或者單獨的指標可能會對應多個不同研究場景。例如 CMU PIE 數據集與 accuracy 指標的組合表示為人臉識別研究場景,IMDB 數據集與 accuracy 指標的組合表示為影評情感分類研究場景。因此,我們將一篇文獻中的數據集和指標進行組合來代表研究場景,進而得到大量冗余的研究場景。
很多指標是同時應用的,比如 precision、recall 等,因此,首先需要將指標進行合并,以減少研究場景的冗余。
我們根據方法與研究場景在文獻中的共現次數構建了方法 - 研究場景矩陣。由于數據集和指標的組合較多,使得研究場景的數量非常大,造成了方法 - 場景矩陣的高維稀疏。為解決該問題,我們借鑒 Nonnegative Matrix Factorization (NMF) [1, 11]和譜聚類[16],構建了降維及聚類算法。
首先,我們將數據集和指標組合成研究場景,根據方法和研究場景共現關系,得到方法 - 研究場景共現矩陣。其次,基于 NMF 和譜聚類對方法進行聚類,得到 500 類方法簇。然后,根據指標 - 方法簇共現矩陣對指標進行譜聚類,得到 50 類指標簇。將指標簇與數據集組合成研究場景,根據方法 - 研究場景共現矩陣對研究場景進行譜聚類,得到 500 類研究場景簇。我們期望每個簇中的研究場景數量大體比較均衡,因此將包含研究場景數量 500 以上的簇再次根據方法 - 研究場景共現矩陣進行譜聚類。一共有 2 個簇中包含的研究場景數量在 500 以上,通過再次聚類后得到 200 類研究場景簇。將這 200 類研究場景簇與其余 498 類研究場景簇合并后得到 698 類研究場景簇 。
3.5 方法簇內路徑圖的生成
方法路徑圖描述了不同但高度相關的方法的演變[28]。在通過上述聚類算法得到的方法簇中,每一類方法簇都是由相同類型方法組成的。在這個簇里面,如果能夠構建一個按照時間的方法演化圖,并且加入數據集信息,將會為相關的研究提供非常有啟發的信息。
本文提出的方法簇內路徑圖的生成過程如下所示:
對于一個方法簇,獲取其包含的所有方法的原始文獻信息:提出時間、方法在提出該方法的論文中所在的章節、該方法對應原始論文使用的數據集 ;
對于該方法簇中的每種方法 M_i,找出該方法原始論文的實驗章節所提到的其它方法 。構建 M_i 到 每個方法的路徑 M_i→M_j, M_j,∈。M_i 與 M_j 之間的邊為 M_i 和 M_j 進行對比時使用的數據集;
合并連續路徑,得到同類方法下方法的路徑圖。(例如, 如果有 (M_1→M_2), (M_2→M_3), (M_1→M_3),只保留(M_1→M_2), (M_2→M_3))。
我們的路徑圖構建同 [28] 中的方法存在兩點區別:1)我們增加了數據集的關系,方法和方法之間通過數據集建立聯系,從而提供了額外的信息;2)我們通過大規模文獻來獲取方法,可以同時得到大量的路徑圖。
3.6 研究場景簇的影響程度
本文分析了研究場景簇之間的影響程度,以及追溯到的有效方法對其他研究場景簇的影響程度。
根據研究場景與研究場景簇的對應關系,我們找出每篇文獻涉及的研究場景所對應的研究場景簇。考慮到一篇論文中一般只涉及 1 類主要的研究場景,因此,我們取每篇文獻出現次數最多的研究場景簇作為該文獻對應的研究場景簇。最終我們得到了 CCF corpus 中 45,215 篇文獻對應的研究場景簇 。結合這 45,215 篇文獻及其提出的有效方法,我們分析了這 45,215 篇文獻中研究場景簇之間的相互影響關系,以及這些文獻提出的有效方法對其他研究場景簇的影響。
我們將研究場景簇為 s 的文獻集合定義為 Ls,。文獻提出的有效方法三年內被 引用,場景簇非 s 的文獻集合為 。研究場景簇 s 對其他研究場景簇 \s 的影響程度比率計算如公式 1 所示:
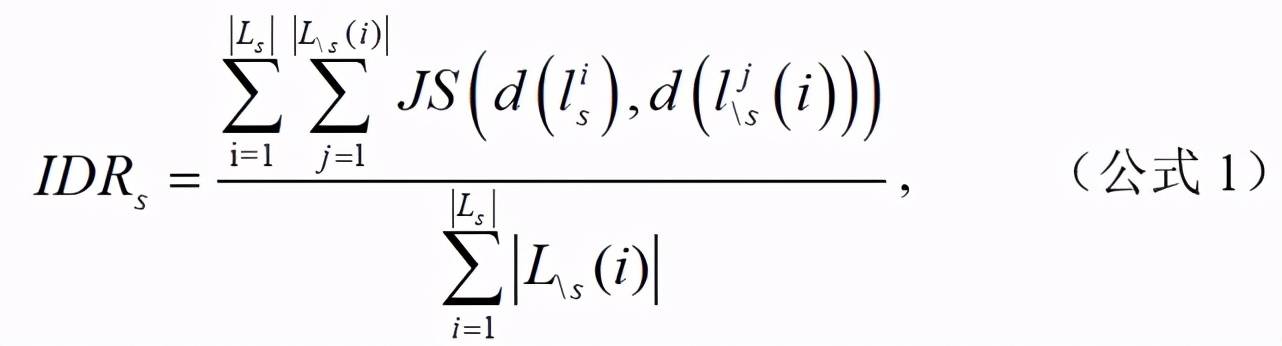
其中,為文獻對應的研究場景簇在 45,215 篇論文中的分布,表示文獻對應的研究場景簇在 45,215 篇論文中的分布。為計算與的 JS 散度。
此外,本文分析了這 45,215 篇文獻提出的有效方法對其他研究場景簇的影響。
我們將有效方法 m 對應的原始文獻表示為 l_m,文獻 l_m 對應的研究場景簇為 s,三年內引用了有效方法 m 且場景簇非 s 的文獻集合為 。有效方法 m 對研究場景簇的影響程度 ID_m 和影響程度比率 IDR_m 計算公式如下:
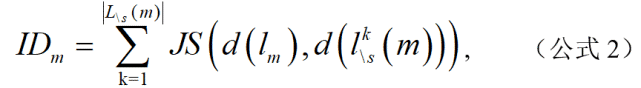
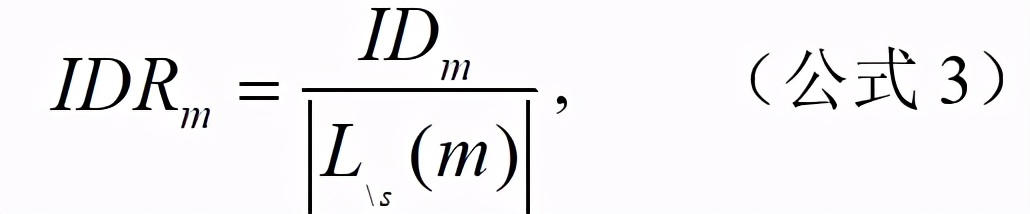
其中,為 l_m 文獻對應的研究場景簇在 45,215 篇論文中的分布,表示為文獻對應的研究場景簇在 45,215 篇論文中的分布。為計算與的 JS 散度。
4 結果
本節基于前述的方法,包括章節分類、AI 標記的抽取與歸一、AI 標記原始文獻的溯源、方法和研究場景的聚類、方法簇內路徑圖的生成以及研究場景簇的影響程度,對所收集的 CCF corpus(2005-2019 年的 AI 論文)進行基于 AI 標記的統計分析、傳播分析與挖掘,并對結果進行展示。
4.1 有效 AI 標記的統計
我們通過提取 CCF corpus 中的 AI 標記,得到 171,677 個機器學習方法實體、16,645 個數據集實體、1551 個指標實體。考慮到很多只出現一次的 AI 標記基本上沒有豐富的信息,我們只對出現 1 次以上的 AI 標記進行分析。我們將出現次數大于 1 的 AI 標記稱為有效 AI 標記。
本節介紹了有效 AI 標記關于國家和出版地點的分析,以及對每年使用數量排名前十的有效 AI 標記的分析。
4.1.1 有效 AI 標記關于國家的分析
一個國家提出有效 AI 標記的數量能夠體現出該國 的 AI 研究實力。因此,我們首先對 CCF corpus 中各個國家在 2005-2019 年提出的有效方法和數據集的數量分別進行了統計,如圖 4 和圖 5 所示。
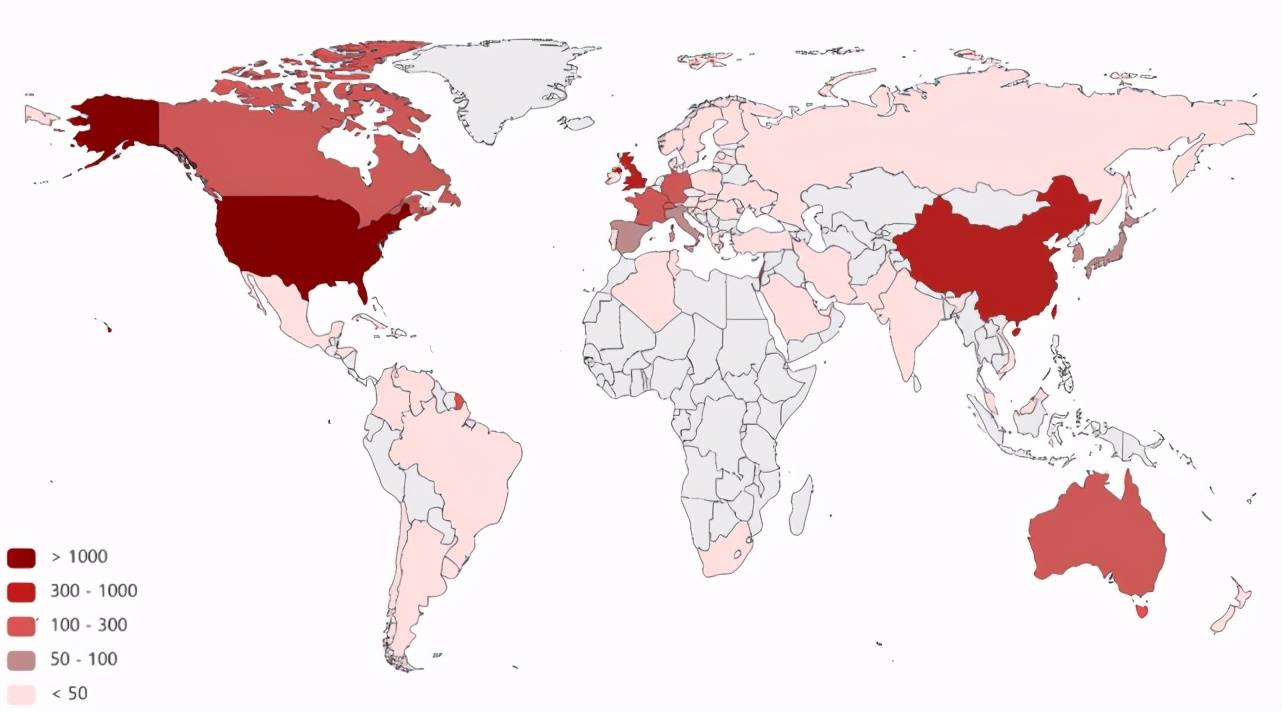
Figure 4:追溯到的由 CCF corpus 提出的有效方法在不同國家中的數量分布
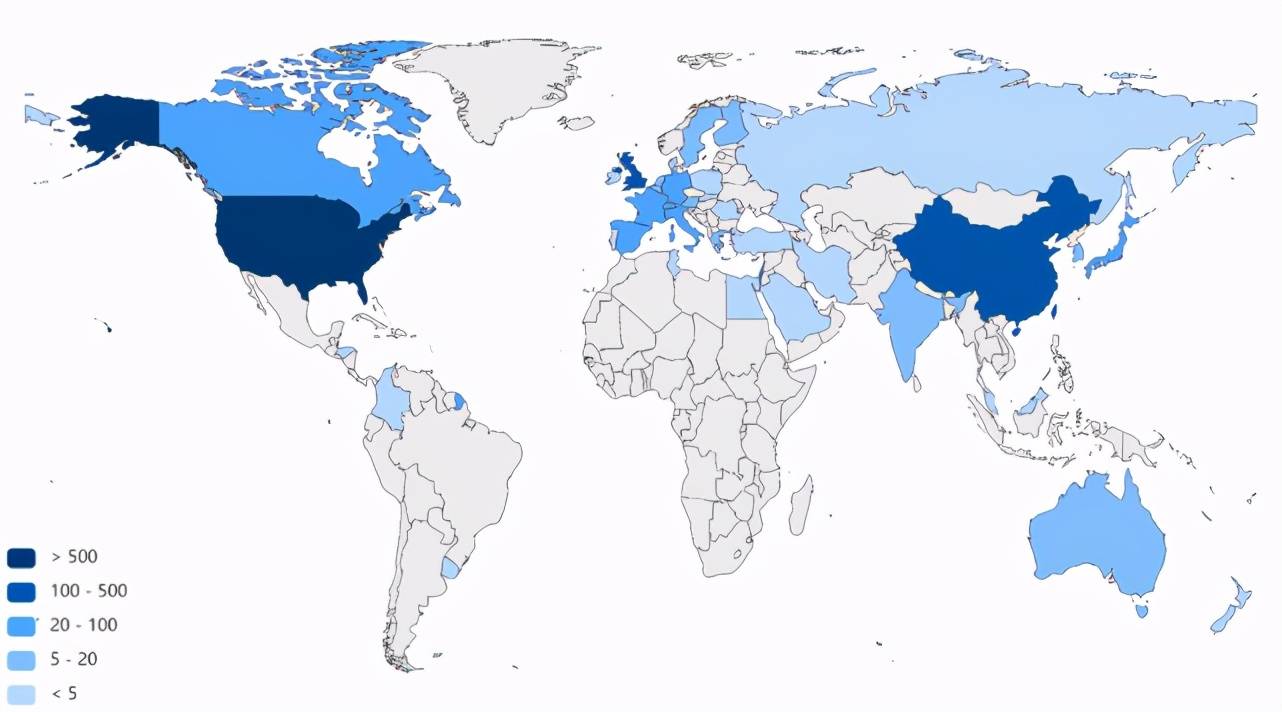
Figure 5:追溯到的由 CCF corpus 提出的有效數據集在不同國家中的數量分布
由圖 4 我們可以看出,提出有效方法的數量排名前三的是美國、中國、英國。德國、法國、加拿大、新加坡、澳大利亞等國家提出的有效方法數量次之。由圖 5 我們可以看出,提出有效數據集的數量排名前三的也是美國、中國、英國。德國、瑞士、加拿大、法國、新加坡、以色列等國家提出的有效數據集的數量次之。由此可以看出,美國、中國、英國是機器學習領域中相對更為活躍的國家。德國、法國、加拿大、新加坡等國家雖與美國、中國、英國有一定差距,但是相對而言也比較活躍。
為了降低各個國家論文發表數量對分析結果產生的影響,我們對 CCF corpus 中提出有效方法數量排名前十的國家的有效方法提出率和 CCF corpus 中提出有效數據集數量排名前十的國家的有效數據集提出率進行了分析。
國家 c 有效方法的提出率 MRc、有效數據集的提出率 DRc 計算如公式 4 和 5 所示。
其中, 表示 CCF corpus 中國家 c 提出的所有有效方法的集合, 表示 CCF corpus 中國家 c 提出的所有有效數據集的集合, 表示在 CCF corpus 中國家 c 的所有文獻的集合。
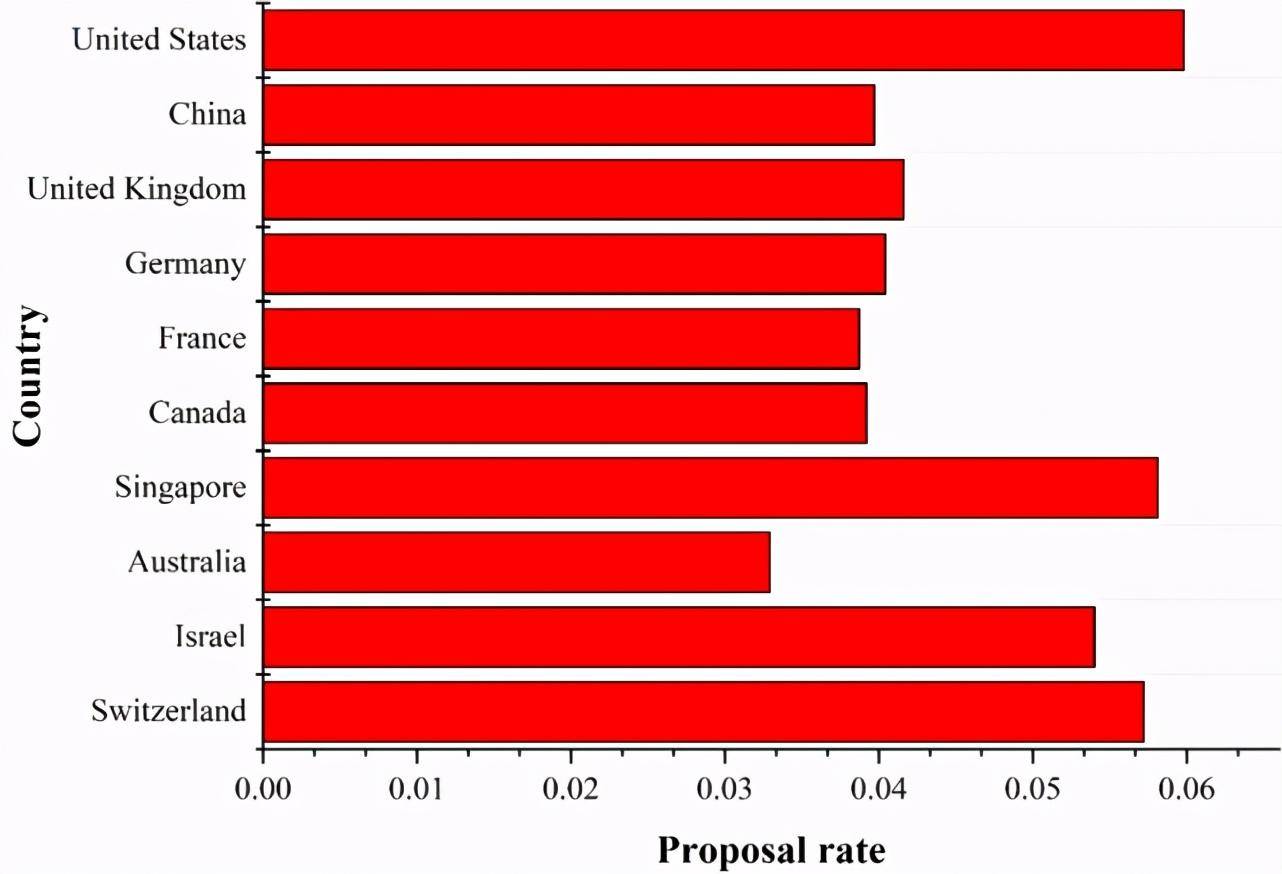
(a) 圖 4 中排名前 10 國家的有效方法提出率。
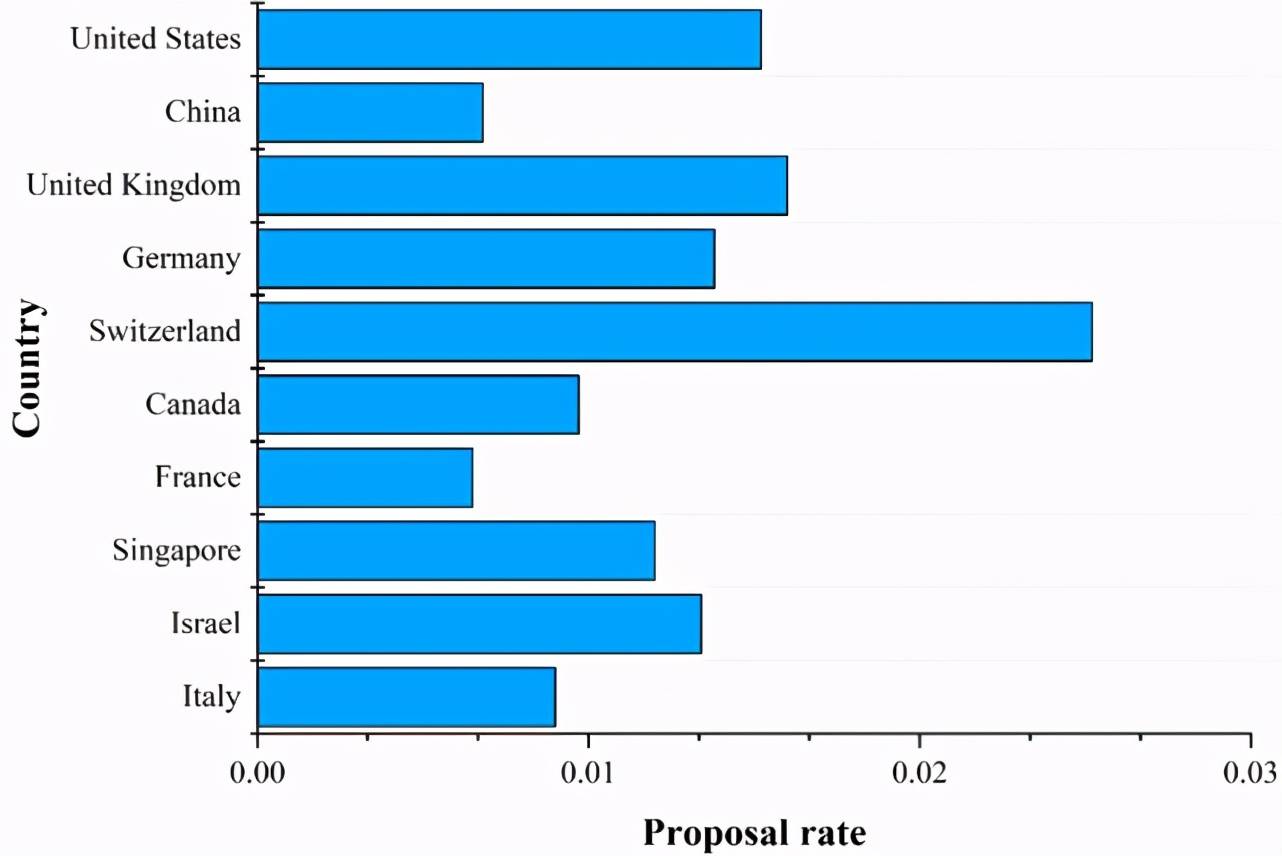
(b) 圖 5 中排名前 10 國家的有效數據集提出率。
Figure 6:圖 4 和圖 5 中排名前 10 國家中有效 AI 標記的提出率。國家提出的 AI 標記的數量從上到下遞減。
基于公式(4)和(5),我們計算了提出有效方法數量排名前 10 的國家中有效方法的提出率和提出有效數據集數量排名前 10 的國家中有效數據集的提出率,結果如圖 6 所示。
由圖 6a 我們可以看出,美國提出有效方法的數量和比例都穩居第一位。中國和英國雖然提出有效方法的數量比較高,但是提出有效方法率要低于新加坡、以色列、瑞士。由圖 6b 可知,瑞士雖然提出有效數據集的數量要低于美國、中國、英國、德國,但是在數據集的提出率上是最高的,反映出瑞士特別重視 AI 數據集。
4.1.2 有效 AI 標記關于出版地點的分析
一個出版地點提出有效 AI 標記的數量能夠體現出該出版地點的質量。出版地點 v 有效方法的提出率 MRv、有效數據集的提出率 DRv 計算如公式 6 和 7 所示。
其中,M_v表示 CCF corpus 中出版地點 v 提出的所有有效方法的集合,D_v表示 CCF corpus 中出版地點提出的所有有效數據集的集合,L_v表示在 CCF corpus 中發表在出版地點 v 的所有文獻的集合。
利用公式 6 和 7,我們計算了提出有效方法數量排名前 10 的出版地點中有效方法的提出率和提出有效數據集數量排名前 10 的出版地點中有效數據集的提出率,結果如圖 7 所示。
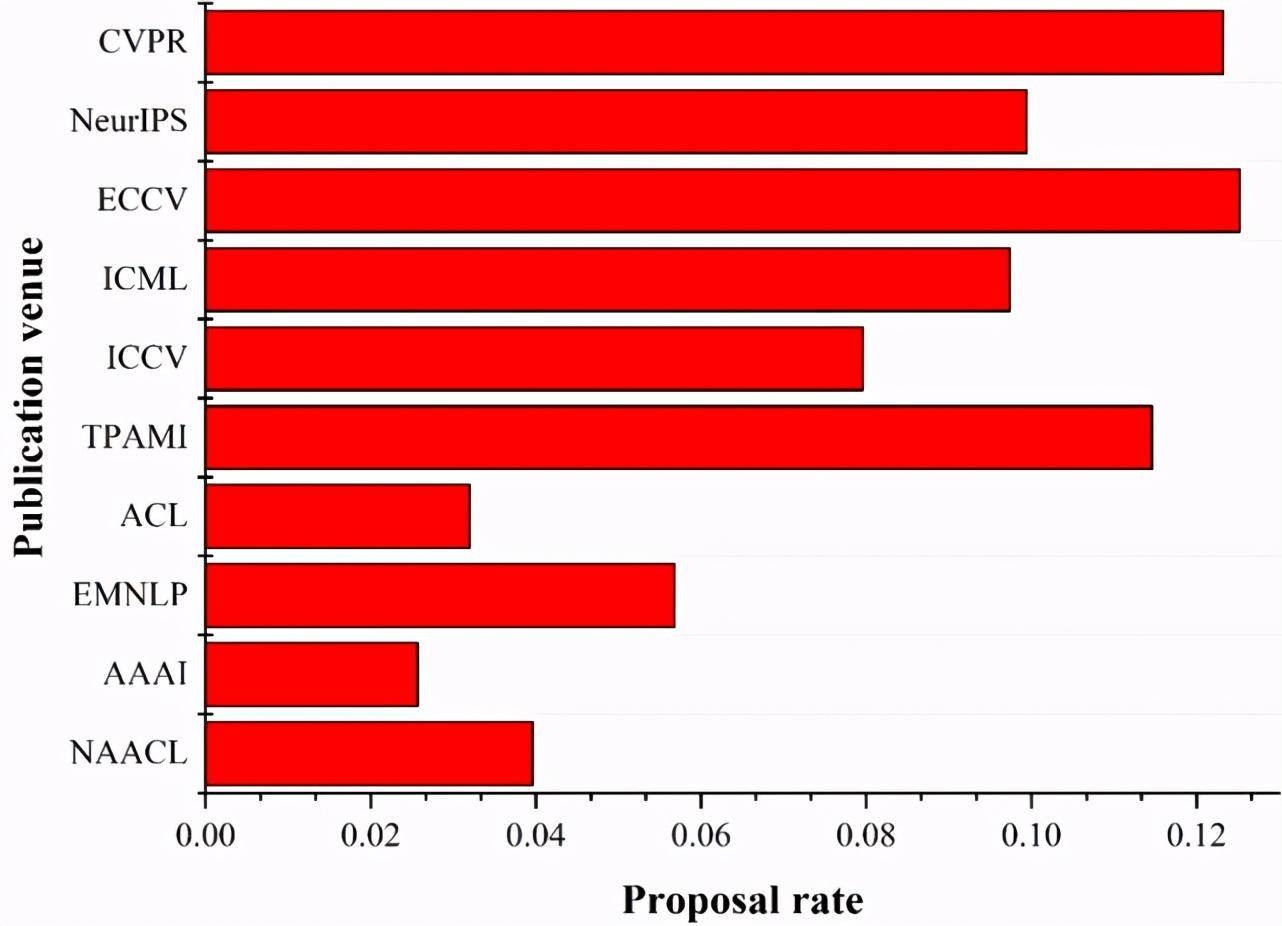
(a) 提出有效方法排名前 10 的出版地點的有效方法提出率。
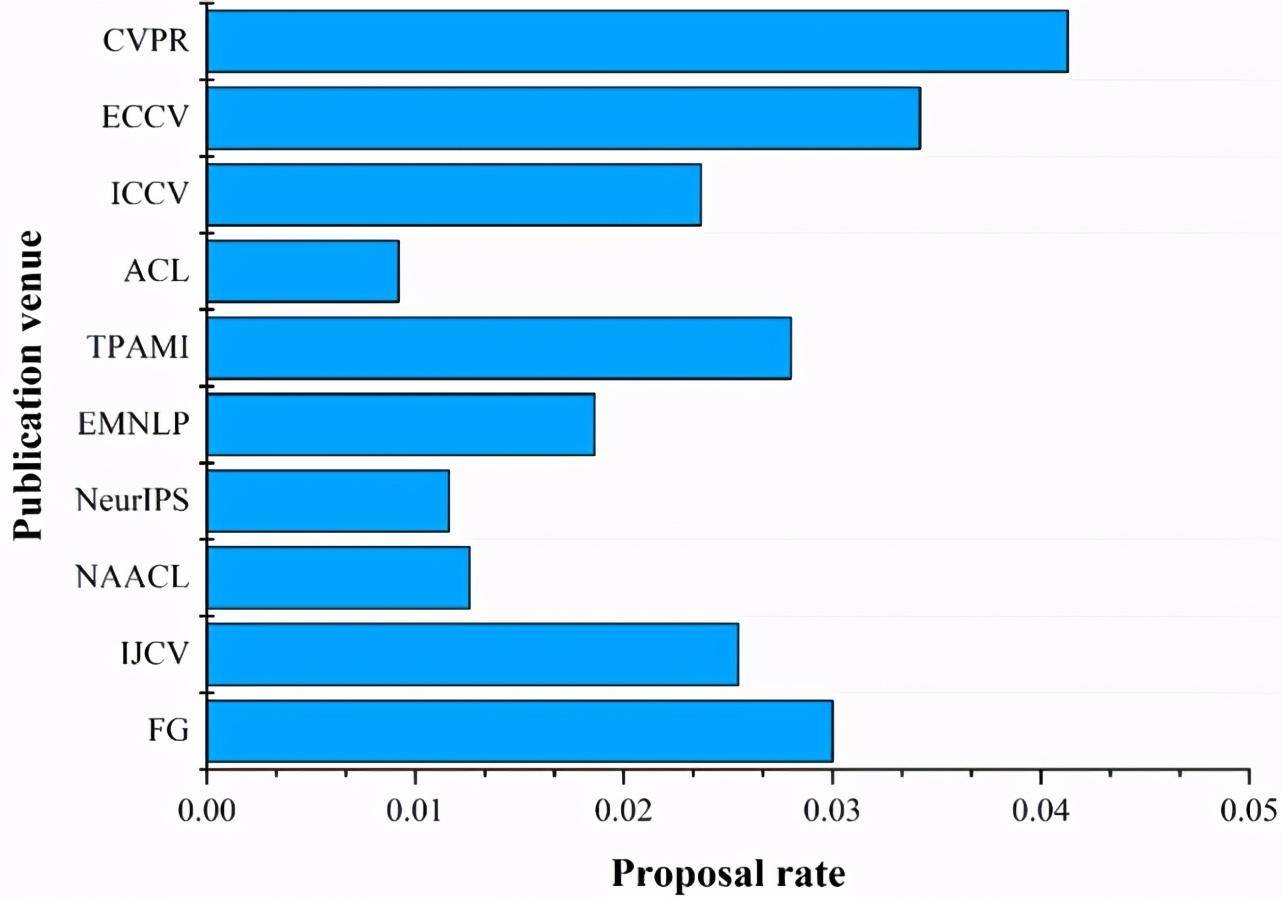
(b) 提出有效數據集排名前 10 的出版地點的有效數據集提出率。
Figure 7:提出有效 AI 標記排名前 10 的出版地點的有效 AI 標記提出率。出版地點提出的 AI 標記的數量從上到下遞減。
由圖 7a 我們可以看出, ECCV 雖然是 CCF 的 B 類會議,但是其有效方法提出率要高于 CVPR。在提出有效方法的數量排名前十的出版地點中,有 7 個都是 A 類的出版地點,這說明 A 類出版地點中的論文質量確實要比 B 和 C 類的高。
圖 7b 展示了有效數據集的分布情況。我們可以看出,CVPR 提出更有效數據集的數量和提出率都排名第一。ECCV 雖然是 B 類會議,但是提出有效數據集的數量和提出率僅次于 CVPR。在提出有效數據集的數量排名前十的出版地點中,有 6 個是 A 類的出版地點,也反映出 A 類出版地點確實更關注有效數據集的提出。
4.1.3 每年使用排名數量前十的有效 AI 標記
本節分別對 2005-2019 年間每年使用的有效方法和有效數據集的數量進行了統計分析。
(1) 每年使用數量排名前 10 的有效方法
我們對 2005-2019 年間每年使用的有效方法數量進行了統計,每年排名前十的有效方法如圖 8 所示。
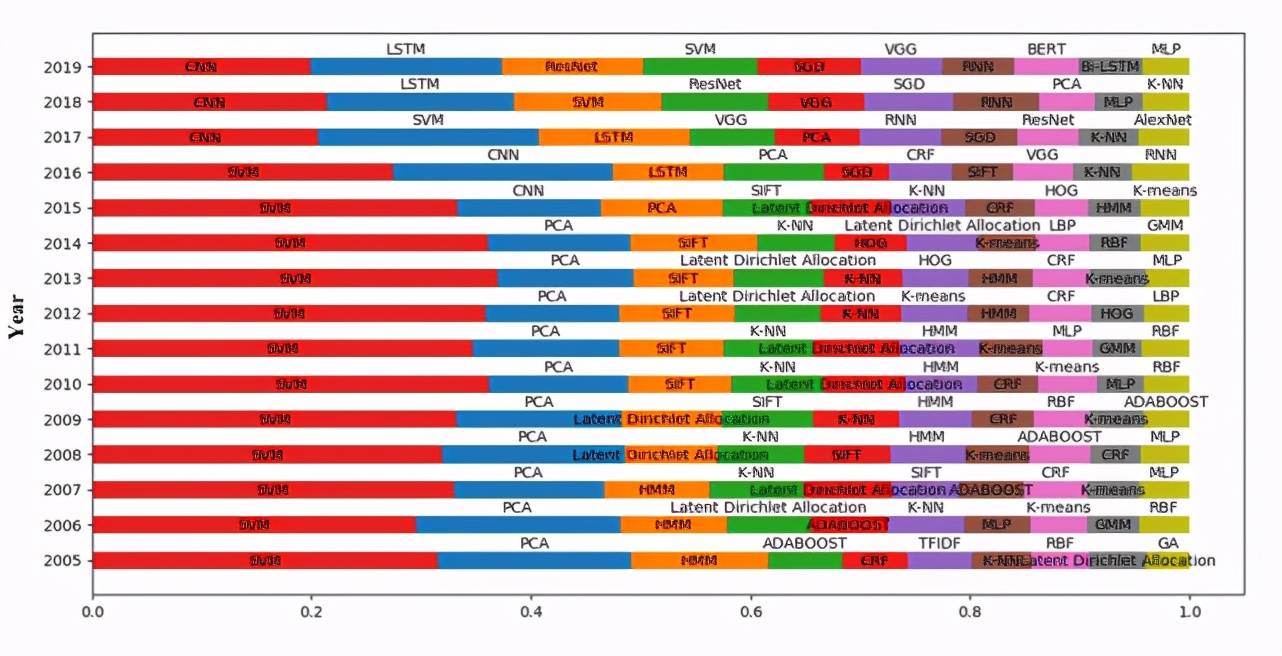
Figure 8:每年使用數量排名前十的有效方法
由圖 8 可以看出,SVM 作為一種傳統的機器學習方法,每年都被廣泛使用。LDA 作為用于文本挖掘的經典的主題模型,在 2005-2015 年間一直被廣泛應用。但是隨著深度學習的快速發展,在 2015 年以后,其使用占比明顯下降。2015 年以后,深度學習越來越流行,深度學習方法成為 AI 領域的主流。
計算機視覺和自然語言處理是 AI 研究中的兩個重要研究學科。由圖 8 可知,計算機視覺中的方法始終占據很大的比例,這表明計算機視覺一直是 AI 的熱門研究分支。
(2) 每年使用數量排名前 10 的有效數據集
我們對每年使用的有效數據集的數量進行了統計,每年排名前十的有效數據集如圖 9 所示。
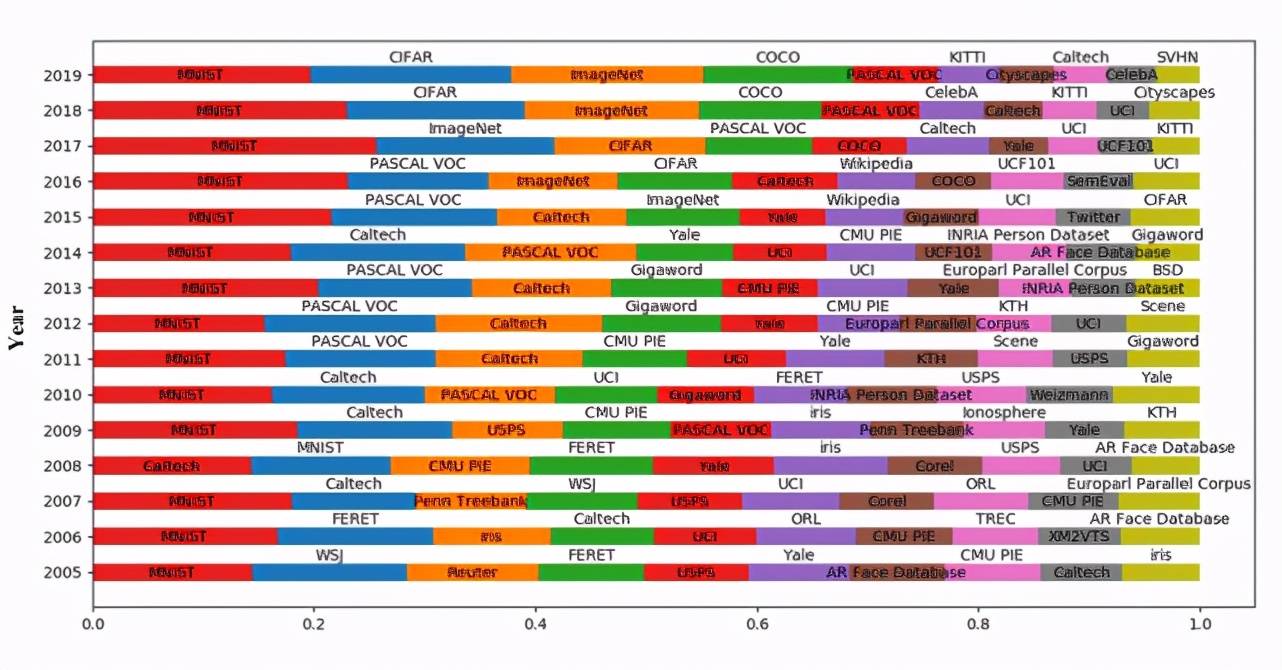
Figure 9:每年使用數量排名前十的有效數據集
由圖 9 可知,MNIST 作為最經典的數據集之一,每年都被普遍使用。2016 年,SemEval 數據集進入了排名前十的行列,而 SemEval 數據集是情感分析常用數據集。由此可看出,2016 年,情感分析受到了廣泛關注。2017 年,KITTI 數據集進入了排名前十的行列,而 KITTI 數據集是無人駕駛領域經典數據集,說明 2017 年無人駕駛領域受到了廣泛關注,并且在 2017-2019 年期間,KITTI 數據集在每年前十數據集中的占比逐漸提高。此外,由該圖我們還可以看出,一般數據集在發布后,至少需要兩年時間才會得到認可和在相應領域的廣泛使用。比如 PASCAL VOC 數據集 2007 年發布,2009 年被廣泛使用;Weizmann 數據集 2006 年發布,2010 年被廣泛使用;COCO 數據集 2014 年發布,2016 年得到廣泛使用。
人臉識別是計算機視覺領域中比較熱門的研究方向。我們對每年排名前 10 的有效數據集中人臉識別數據集的占比情況進行了統計,如表 5 所示。
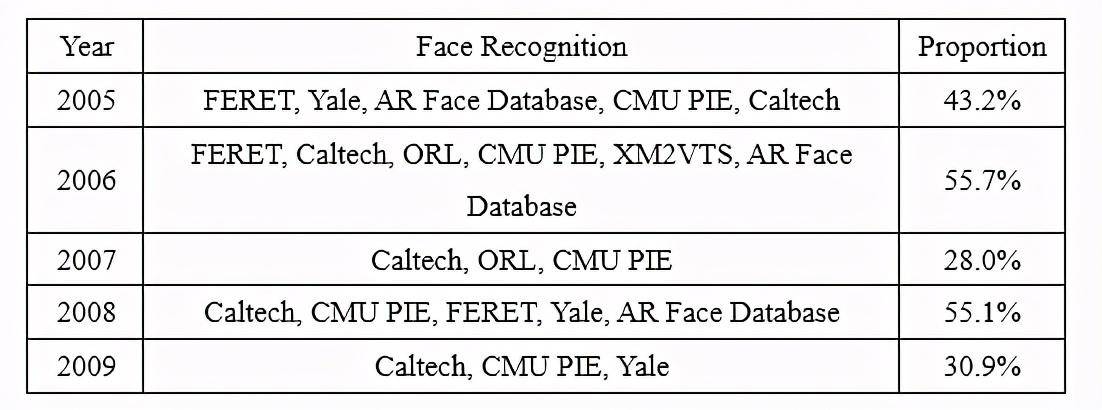
Table 5:每年排名前 10 的有效數據集中人臉識別數據集的占比
表 5 顯示,2005-2019 年人臉識別的常用數據集有 Caltech、Yale、CMU PIE、CelebA。Caltech 在每年排名前十的有效數據集中均出現且占比都較高。Yale 出現的年份也很多,但是在 CelebA 數據集出現后,其地位就被 CelebA 替代。
4.2 有效方法的傳播
本節對有效方法在數據集上的傳播和在國家之間的傳播分別進行了分析 。
4.2.1 在數據集上的傳播
我們對 2005 年到 2019 年每年由 CCF corpus 中的文獻提出的有效方法在數據集上的傳播情況進行了分析。y 年提出的有效方法于 y 到 y+△y 時間區間內在數據集上的傳播率計算公式如下:
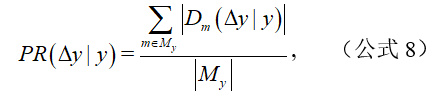
其中,M_y 表示所有在 y 年被提出的方法,表示在 y 到 y+△y 時間區間內被應用在方法 m 上的數據集集合,。
基于公式 8,我們得到每年由 CCF corpus 提出的有效方法一年內、兩年內、三年內在數據集上的傳播率,如圖 10 所示。
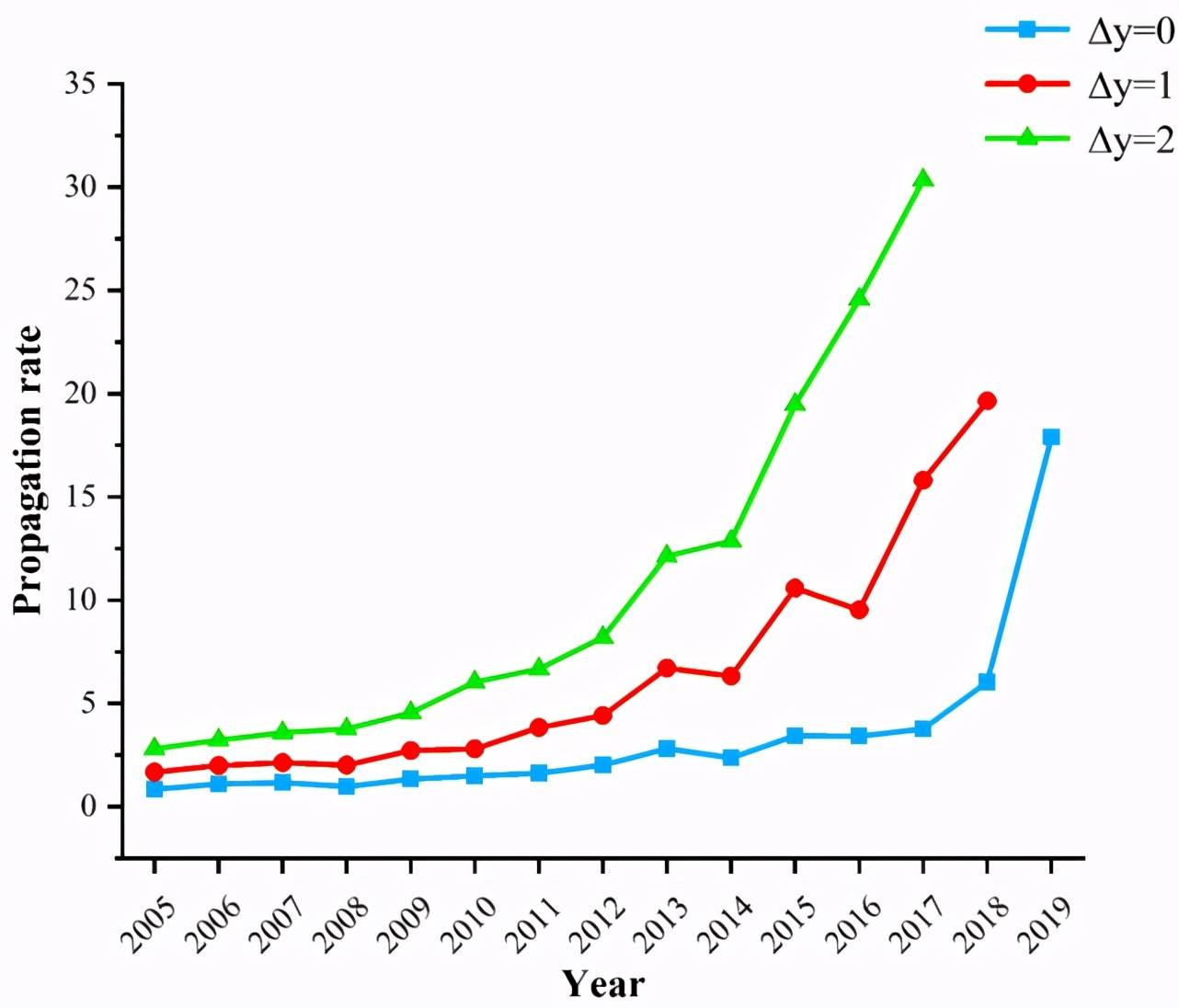
Figure 10:有效方法在數據集上的傳播率
由圖 10 可知,隨著時間的發展,有效方法在數據集上的傳播率呈逐漸上升的趨勢,各種知名方法在文獻未正式發表以前就通過類似 arxiv 的渠道為人們熟知。
此外,我們還對 2005 年由 CCF corpus 中原始文獻提出的 Large margin nearest neighbor (LMNN) 方法和 2018 年由 CCF corpus 中原始文獻提出的 Transformer 方法從傳播到其他文獻開始,兩年內在數據集上的應用情況進行了對比,如圖 11 所示。
由圖 11 可知,Transformer 在 2018 年被提出后,2018 年和 2019 年被應用在了很多不同數據集上。然而 2005 年被提出的 LMNN,在 2006 年才開始被其他文獻引用,應用在不同的數據集上。并且,我們還可以明顯看出,Transformer 從傳播到其他文獻開始,兩年內在數據集上的應用數量和種類要遠多于 LMNN。這也反映出隨著時間的發展,方法在數據集上的傳播速度越來越快。
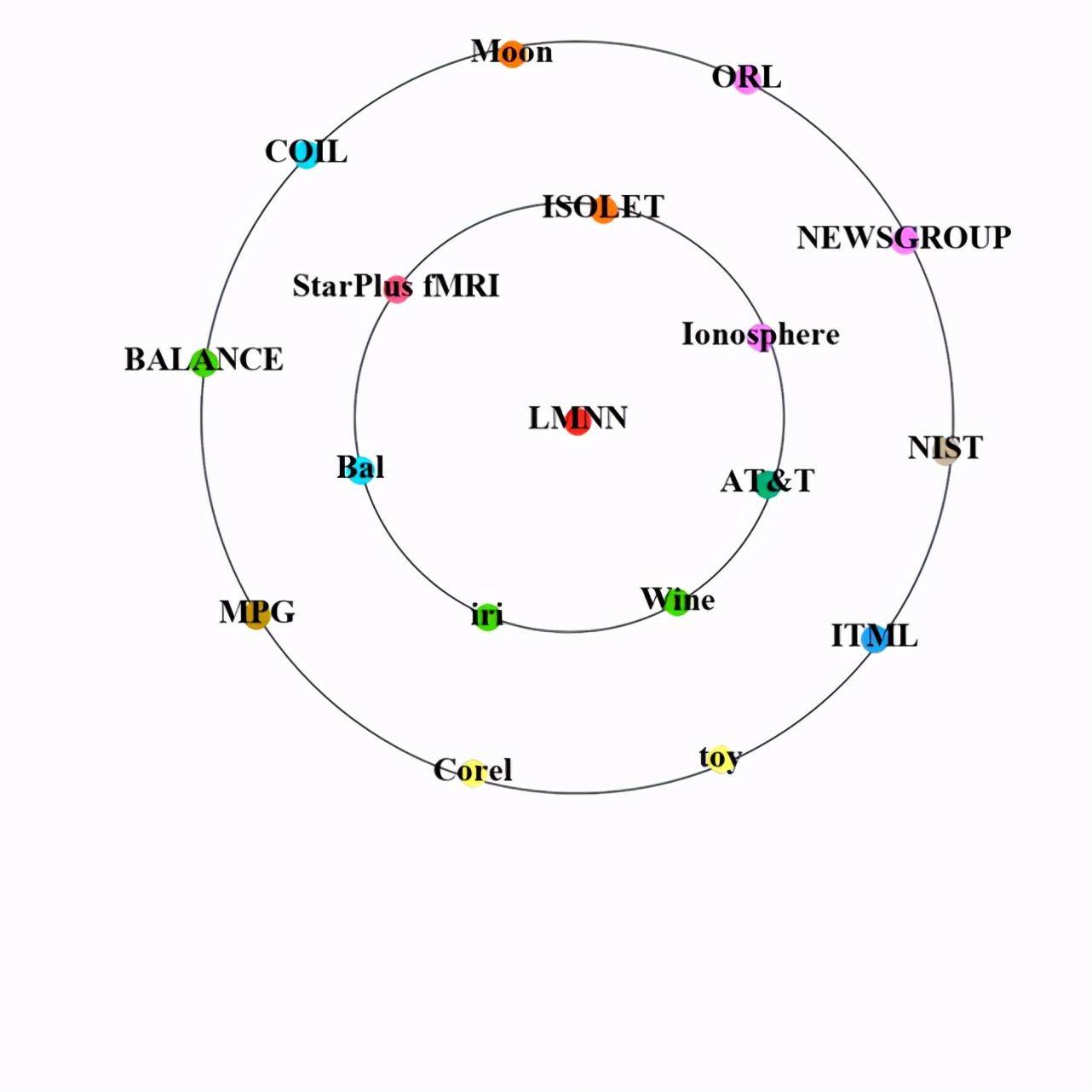
a) LMNN 2006 年(內圈)和 2007 年應用的數據集。
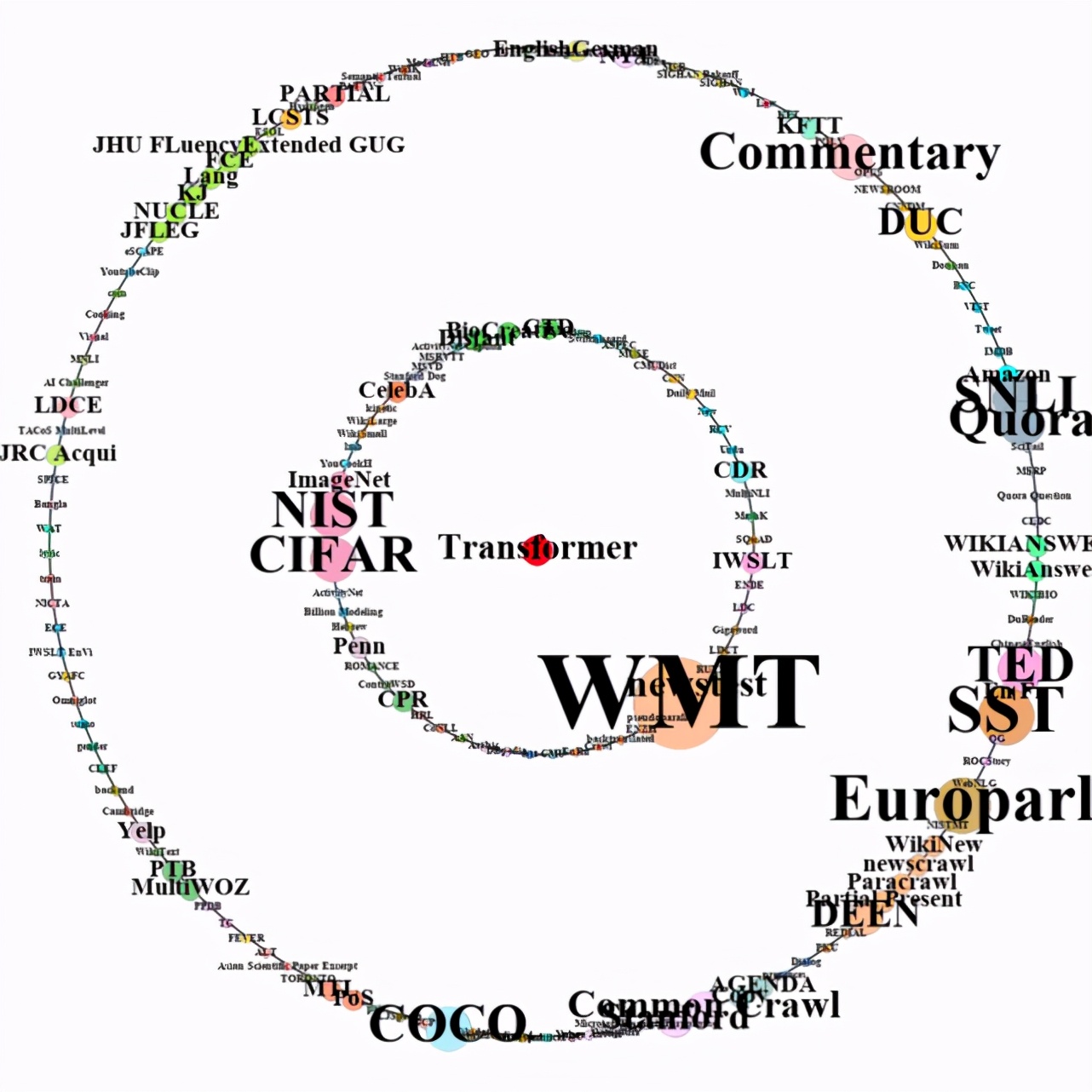
b) Transformer 2018 年(內圈)和 2019 年應用的數據集。
Figure 11:有效方法應用的數據集,中間的紅點表示方法。內圈和外圈由許多數據集點組成,在數據集點中,點的大小表示該方法應用的數據集的數量,不同數據集點的顏色表示不同的研究場景。
4.2.2 在國家間的傳播
本節對有效方法在國家間的傳播進行了分析。我們將國家 c 提出的所有有效方法的集合定義為M_c,。在 y 到 y+△y 時間區間內,有效方法由國家 c 到國家 c’ 的傳播程度的計算如公式 9 所示。
其中為在 y 到 y+△y 時間區間內,在實驗章節引用了 m 的 c’ 國論文集合。為在 y 到 時間區間內,在方法介紹章節引用了 m 的 c’ 國論文集合, 。
基于公式 9,我們以 5 年為一個階段,對 2005-2009 年、2010-2014 年、2015-2019 年有效方法在國家之間的傳播程度進行了計算。每個階段排名前十的國家之間有效方法傳播程度如圖 12 所示。
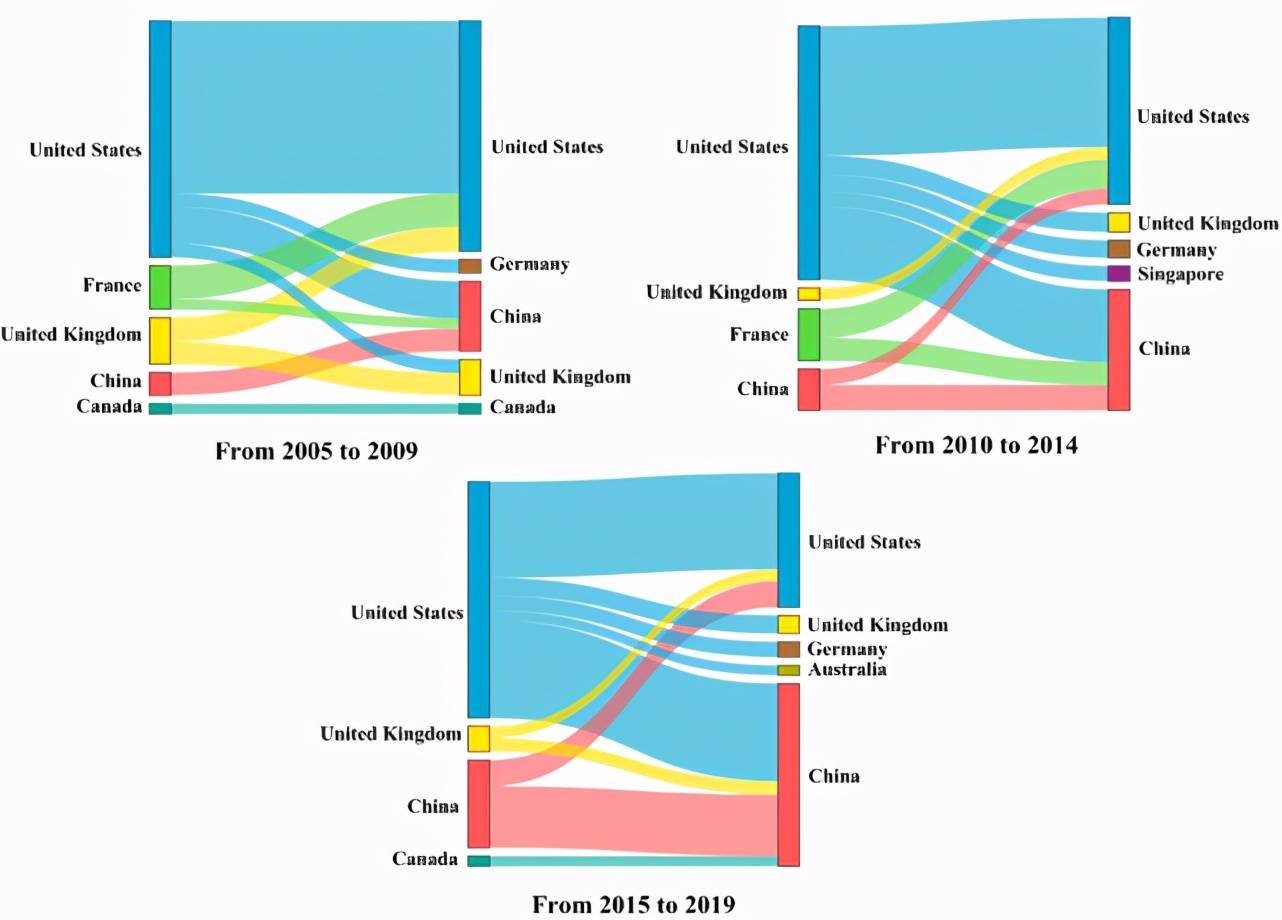
Figure 12:2005 年到 2019 年,有效方法在國家之間的傳播程度的 top10。
從圖 12 可以看出,有效方法在 2005-2009 年更多地從美國、法國和英國傳播到其他國家。相對而言,中國提出的有效方法傳播程度較低。在 2010-2014 年,中國提出方法的傳播程度逐漸增大,并且到了 2015-2019 年,中國提出方法對美國的傳播程度躍到了第四位。反映出中國的 AI 發展越來越好。相反,法國提出的方法在 2005-2014 年傳播程度比較大。而到了 2015-2019 年,法國提出的方法的傳播程度排到了十名以后,反映出近幾年法國的 AI 發展相對較慢。
4.3 路徑圖和研究場景的結果
本節介紹了方法的路徑圖和關于研究場景簇的分析。
4.3.1 方法路徑圖的案例研究
我們對知識圖譜中的知識表示學習和生成對抗這兩個常見的方法類進行了分析。利用我們提出的路徑圖生成算法對'Trans' 簇和'GAN' 簇內的方法路徑圖進行了繪制。
圖 13 是'Trans' 簇中的方法路徑圖。經與 Ji 等人 [9] 發表的文獻內容核對,'Trans' 簇中的方法路徑圖包含上述論文提到的 76% 的知識表示學習算法,同時也包含一些與知識表示學習相關的方法。例如:GMatching 和 KGE 是圖嵌入方法,HITS 是鏈接分析方法。
此外,由圖 13 可以直觀看到每個方法的提出時間,例如:TransE 在 2013 年提出,TransH2014 年提出。同時,我們可以看到 TransE 方法節點的出度最大,一方面說明很多方法比如 CTransR、RTRANSE 等是從 TransE 方法受到啟發,進而拓展出新方法。另一方面,也說明 TransE 是代表性知識表示學習方法,很多新提出的知識表示類方法常與其進行對比。此外,從圖中,我們也可以看出'Trans' 簇中的方法使用的數據集情況。
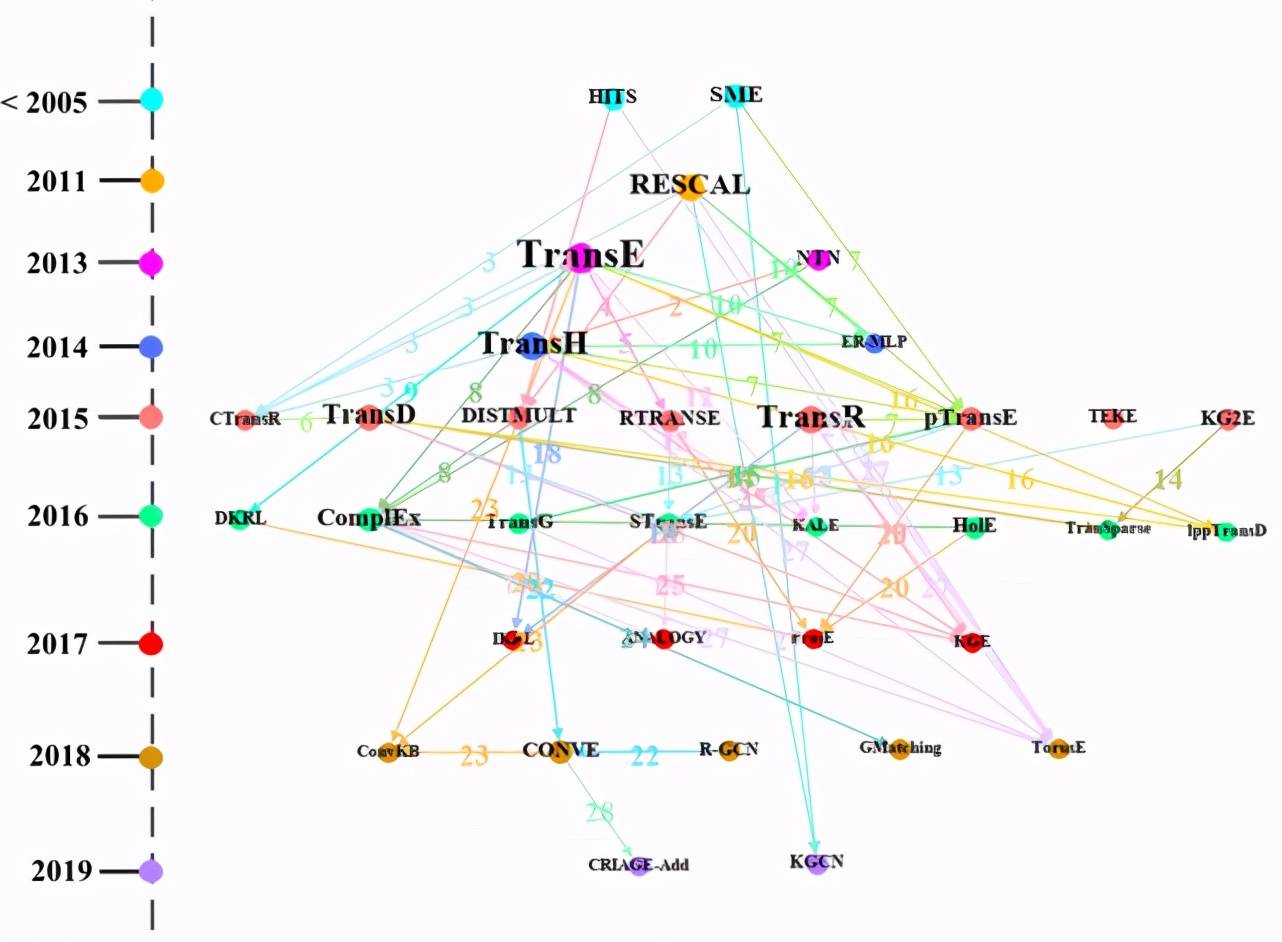
Figure 13:'Trans' 簇中方法的路徑圖,圖中點的顏色表示年份,點的大小表示出度,線的顏色表示數字代表的數據集。
圖中數字表示路徑 Mi→Mj 中 Mi 和 Mj 進行對比時使用的數據集,具體為:1: WIKILINKS 2: WIKILINKS;WN;FB 3: WordNet;FB;WN;Freebase 4: ClueWeb 5: Family 6: FB;WN 7: Freebase;NYT;YORK 8: WordNet;Freebase;WN 9:null 10: RESCAL;WordNet;WN 11: Freebase 12: WordNet;Freebase 13: ClueWeb;WN 14: FB;WN 15: WordNet;FB;WN;Freebase 16: FB;WN 17: null 18: KG;ImageNet;WN 19: null 20: DBpedia 21: FB;WN 22: WN;YAGO;WNRR 23: WNRR;HIT;MR
24: Wikione;NELLone;NELL 25: WNRR;WN 26: WordNet;WN 27: WordNet;Freebase;WN 28: YAGO
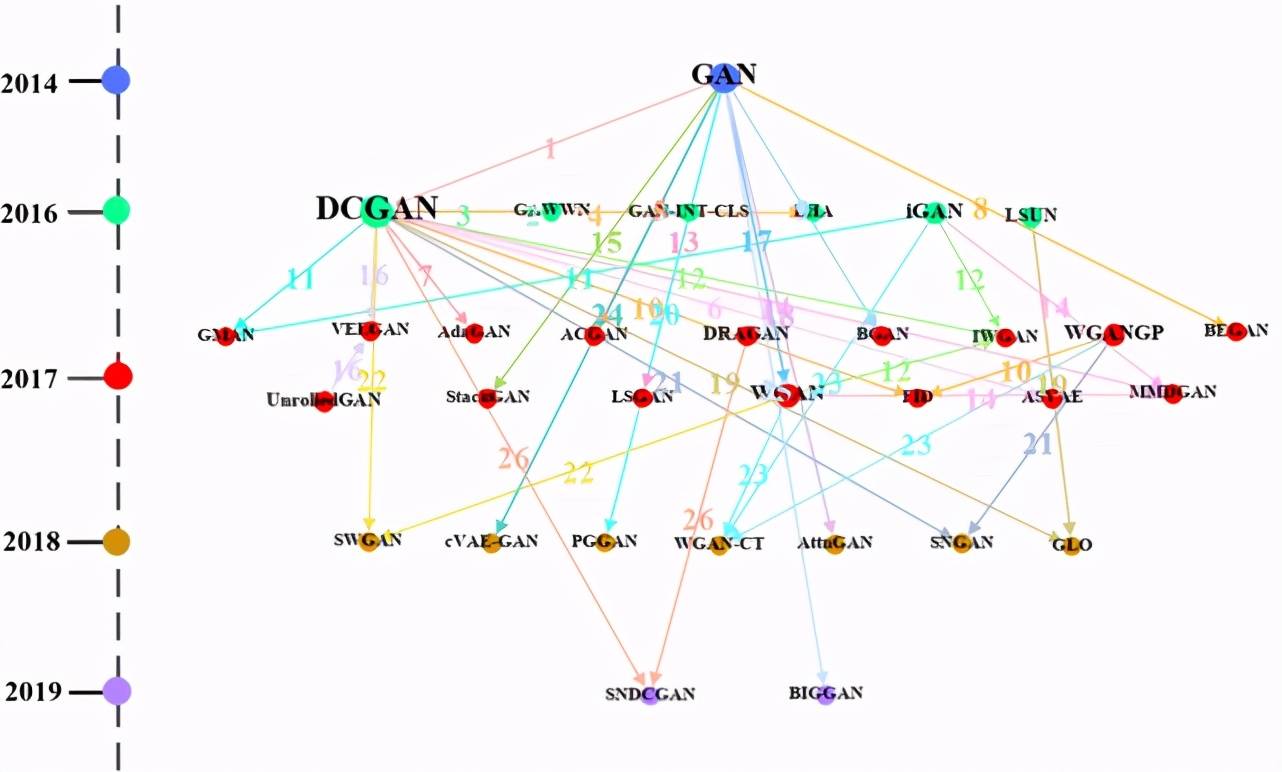
Figure 14:'GAN' 簇中方法的路徑圖,圖中點的顏色表示年份,點的大小表示出度,線的顏色表示數字代表的數據集。
圖中數字表示路徑 Mi→Mj 中 Mi 和 Mj 進行對比時使用的數據集,具體為:1: Face;NIST;SVHN;CelebA 2: CUB(CU Bird);Oxford Flower;Oxford 3: CUB(CU Bird);MPII Human;Caltech;MHP(Maximal Hyperclique Pattern) 4: ILSVRC;SVHN 5: ImageNet 6: NIST;CIFAR;ImageNet 7: NIST 8: CelebA 9: NIST;CIFAR;SVHN 10: BLUR;LSUN;SVHN;CIFAR;Noise;CelebA;LSUN Bedroom 11: NIST;SVHN;CIFAR 12: Google;LSUN;LSUN Bedroom 13: Google 14: NIST;LSUN;CIFAR;CelebA;LSUN Bedroom 15: CUB(CU Bird);Oxford 16: NIST;CIFAR 17: LSUN;CIFAR;LSUN Bedroom 18: ImageNet;COCO 19: NIST;SVHN;LSUN;CelebA;LSUN Bedroom 20: LSUN;CelebA;LSUN Bedroom 21: null 22: NIST;LSUN;CIFAR;CelebA;LSUN Bedroom 23: NIST;SVHN;CIFAR 24: poem;Chinese Poem 25: CONFER 26: null
圖 14 是'GAN' 簇中的方法路徑圖。經與 Hong 等人 [7] 發表的文獻內容核對,'GAN' 簇中方法的路徑圖包含上述論文提到的 75% 的生成對抗類算法。此外,由圖 14 可以直觀看到每個方法的提出時間,例如:GAN 是 2014 年提出的,DCGAN 是 2016 年提出的。同時,我們可以看到 DCGAN 方法節點的出度最大。一方面說明很多方法比如 AdaGAN、SNDCGAN 是從 DCGAN 受到啟發,進而拓展出新方法。另一方面,也可以發現,DCGAN 作為生成對抗的代表性方法,很多新提出來的生成對抗類方法常與 DCGAN 進行對比。此外,從圖中,我們也可以看出'GAN' 簇中的方法使用的數據集情況。
4.3.2 研究場景簇的結果
由 3.6 節中的公式 1,我們得到了研究場景簇之間的相互影響強度比率。考慮到只被 1 篇原始文獻影響或者包含的研究場景數量過少的研究場景簇含有的信息量不多,包含的研究場景數量過多的研究場景簇內含有的研究場景信息比較雜亂。為保證結果的合理性,我們只對包含的場景數量介于 15-20 之間(包含 15 和 20)的研究場景簇進行分析。
得到最容易受其他研究場景簇影響的 top3 研究場景簇:顏色恒常性、圖像記憶性預測、多核學習,以及最不容易受其他研究場景簇影響的 top3 研究場景簇:顯著性檢測、行人重識別、人臉識別。
由 3.6 節中的公式 2 和 3,我們對由 45,215 篇論文提出的有效方法對其他研究場景簇的影響強度和影響強度比率分別進行了計算。每年影響強度最大的方法信息如表 7 所示,每年影響強度比率最大的方法信息如表 8 所示。
Table 7:每年影響強度最大的方法信息
Table 8:每年影響強度比率最大的方法信息
由表 7 和表 8 我們可以發現,2005-2019 年每年對其他研究場景簇影響強度最大的方法中,有 12 個方法都與計算機視覺相關;影響強度比率最大的方法中,有 10 個方法都與計算機視覺相關。這說明計算機視覺類方法相對于其他類方法而言更容易影響其他研究場景簇。此外,從出版地點角度來看,表 7 中的 15 篇文獻中 12 篇來自于 A 類出版地點,表 8 中的 15 篇文獻中 14 篇來自于 A 類出版地點,這說明A 類出版地點提出的方法更容易對其他研究場景簇產生影響。
5 結論和未來工作
本文借鑒生物領域中通過標記物來追蹤反應過程中物質和細胞的變化,從而獲取反應特征和規律的思想,將 AI 文獻中的方法、數據集、指標實體作為 AI 領域的標記物,利用這三種同粒度命名實體在具體研究過程中的蹤跡來研究 AI 領域的發展變化情況。
我們首先利用 AI 標記抽取模型對 122,446 篇論文中方法章節和實驗章節的 AI 標記進行提取,對提取的有效方法和數據集進行統計分析,獲得反映 AI 領域年度發展情況的重要信息。其次,我們對有效方法和數據集進行了原始文獻的溯源,對原始文獻進行了計量分析。并挖掘了有效方法在數據集上和在國家之間的傳播規律。發現新加坡、以色列、瑞士等國家提出的有效方法數量相對很多;隨著時間的發展,有效方法在應用在不同數據集上的速度越來越快;中國提出的有效方法對其他國家的影響力越來越大,而法國恰好相反。最后,我們將數據集和指標進行組合作為 AI 研究場景,對方法和研究場景分別進行聚類。基于方法聚類及關聯數據集繪制路徑圖,研究同類方法的演化關系。基于研究場景的聚類結果來分析方法對研究場景以及研究場景之間的影響程度,發現顯著性檢測這種經典的計算機視覺研究場景最不容易受其他研究場景的影響。
在以后的工作中,我們將對 AI 標記抽取模型進行改進,優化其抽取性能,并嘗試從 AI 文獻的表格、圖像等部分提取 AI 標記,更全面、準確地實現對 AI 標記的提取,進而更準確地展示 AI 領域的發展情況。
參考文獻
[1] Fatemah Alghamedy and Jun Zhang. 2018. Enhance NMF-based recommendation systems with social information imputation. Computer Science & Information Technology (CS & IT). AIRCC (2018), 37–54. https://doi.org/10.5121/csit.2018.81503
[2] Dheeru Dua, YizhongWang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. 2019. DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. arXiv preprint arXiv:1903.00161 (2019).
[3] Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, and Noah A Smith. 2015. Transition-based dependency parsing with stack long short-term memory. arXiv preprint arXiv:1505.08075 (2015).
[4] Masaki Eto. 2016. Rough co-citation as a measure of relationship to expand co-citation networks for scientific paper searches. Proceedings of the Association for Information Science and Technology 53, 1 (2016), 1–4. https://doi.org/10.1002/pra2.2016.14505301131
[5] Thomas L Griffiths and Mark Steyvers. 2004. Finding scientific topics. Proceedings of the National academy of Sciences 101, suppl 1 (2004), 5228–5235. https://doi.org/10.1073/pnas.0307752101
[6] David Hall, Dan Jurafsky, and Christopher D Manning. 2008. Studying the history of ideas using topic models. In Proceedings of the 2008 conference on empirical methods in natural language processing. 363–371. https://doi.org/10.3115/1613715.1613763
[7] Yongjun Hong, Uiwon Hwang, Jaeyoon Yoo, and Sungroh Yoon. 2019. How generative adversarial networks and their variants work: An overview. ACM Computing Surveys (CSUR) 52, 1 (2019), 1–43. https://doi.org/10.1145/3301282
[9] Shaoxiong Ji, Shirui Pan, Erik Cambria, Pekka Marttinen, and Philip S Yu. 2020. A survey on knowledge graphs: Representation, acquisition and applications. arXiv preprint arXiv:2002.00388 (2020).
[10] John Lafferty, Andrew McCallum, and Fernando CN Pereira. 2001. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning. 282–289.
[11] Daniel D Lee and H Sebastian Seung. 2001. Algorithms for non-negative matrix factorization. In Advances in neural information processing systems. 556–562.
[12] Xinyi Li, Yifan Chen, Benjamin Pettit, and Maarten De Rijke. 2019. Personalised reranking of paper recommendations using paper content and user behavior. ACM Transactions on Information Systems (TOIS) 37, 3 (2019), 1–23. https://doi.org/10.1145/3312528
[13] Jiaying Liu, Jing Ren, Wenqing Zheng, Lianhua Chi, Ivan Lee, and Feng Xia. 2020. Web of scholars: A scholar knowledge graph. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2153–2156. https://doi.org/10.1145/3397271.3401405
[15] Xuezhe Ma and Eduard Hovy. 2016. End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv preprint arXiv:1603.01354 (2016).
[16] Andrew Y Ng, Michael I Jordan, and YairWeiss. 2002. On spectral clustering: Analysis and an algorithm. In Advances in neural information processing systems. 849–856.
[17] Jeffrey Pennington, Richard Socher, and Christopher D Manning. 2014. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 1532–1543. https://doi.org/10.3115/v1/D14-1162
[20] Lei Shi, Hanghang Tong, Jie Tang, and Chuang Lin. 2015. Vegas: Visual influence graph summarization on citation networks. IEEE Transactions on Knowledge and Data Engineering 27, 12 (2015), 3417–3431. https://doi.org/10.1109/TKDE.2015.2453957
[21] Mark Steyvers, Padhraic Smyth, Michal Rosen-Zvi, and Thomas Griffiths. 2004. Probabilistic author-topic models for information discovery. In Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining. 306–315. https://doi.org/10.1145/1014052.1014087
[22] Cassidy R Sugimoto, Daifeng Li, Terrell G Russell, S Craig Finlay, and Ying Ding. 2011. The shifting sands of disciplinary development: Analyzing North American Library and Information Science dissertations using latent Dirichlet allocation. Journal of the American Society for Information Science and Technology 62, 1 (2011), 185–204. https://doi.org/10.1002/asi.21435
[23] Jie Tang, Jing Zhang, Limin Yao, Juanzi Li, Li Zhang, and Zhong Su. 2008. Arnetminer: extraction and mining of academic social networks. In Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. 990–998. https://doi.org/10.1145/1401890.1402008
[25] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ?ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems. 5998–6008.
[26] Rui Yan, Jie Tang, Xiaobing Liu, Dongdong Shan, and Xiaoming Li. 2011. Citation count prediction: learning to estimate future citations for literature. In Proceedings of the 20th ACM international conference on Information and knowledge management. 1247–1252. https://doi.org/10.1145/2063576.2063757
[28] Hanwen Zha, Wenhu Chen, Keqian Li, and Xifeng Yan. 2019. Mining Algorithm Roadmap in Scientific Publications. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1083–1092. https://doi.org/10.1145/3292500.3330913
[29] Huan Zhao, Xueying Tian, Lingjuan He, Yan Li, Wenjuan Pu, Qiaozhen Liu, Juan Tang, Jiaying Wu, Xin Cheng, Yang Liu, et al. 2018. Apj+ vessels drive tumor growth and represent a tractable therapeutic target. Cell reports 25, 5 (2018), 1241–1254. https://doi.org/10.1016/j.celrep.2018.10.015
[31] Bin Zheng, David C McLean, and Xinghua Lu. 2006. Identifying biological concepts from a protein-related corpus with a probabilistic topic model. BMC bioinformatics 7, 1 (2006), 58. https://doi.org/10.1186/1471-2105-7-58
附錄 A. 歸一化策略
1 方法
1) 除了「C4.5」、「ID3」等特殊方法以外,其余方法去除數字。如果方法是復數形式,則將其轉換為單數形式。例如,「SVMs」歸一化成「SVM」。
2) 將去除數字和轉為單數形式后,小寫化形式相同的方法歸一化成同一種形式。
3) 將詞組中全由小寫字母構成的單詞去除后,小寫化形式相同的方法歸一化成同一種形式。
4) 取詞組中每個單詞的首字母(如果該單詞全由大寫字母組成,則取該單詞的全部字母),查詢所有方法中是否存在唯一與之對應的單詞(即查找全稱對應的唯一縮寫)。若存在,則將縮寫與全稱都歸一化成「縮寫(全稱)」。例如將「Long Short-Term Memory」和「LSTM」,都歸一化成「LSTM (Long Short-Term Memory)」。
2 數據集
1) 去除數據集中的數字。如果數據集是復數形式,則將其轉換為單數形式。例如,「COLT 2011」歸一化成「COLT」。
2) 將去除數字和復數后,小寫化形式相同的數據集歸一化成同一種形式。
3) 如果詞組中有單詞以大寫字母開頭,則只保留詞組中以大寫字母開頭的單詞。例如,「Yale face」歸一化成「Yale」。
4) 取詞組中每個單詞的首字母(如果該單詞全由大寫字母組成,則取該單詞的全部字母),查詢所有數據集中是否存在唯一與之對應的單詞(即查找全稱對應的唯一縮寫)。若存在,則將縮寫與全稱都歸一化成「縮寫(全稱)」。
3 指標
1) 去除指標中的數字。如果指標是復數形式,則將其轉換為單數形式。例如,「error rates」歸一化成「error rate」。
2) 將去除數字和復數后,小寫化形式相同的指標歸一化成同一種形式。
3)只要指標中包含 recall、accuracy、precision、speed 或 error rate 這幾個詞,就把指標都分別歸一化成「recall」、「accuracy」、「precision」、「speed」、「error rate」。例如,「mean accuracy」、「predictive accuracy」等包含「accuracy」的指標都歸一化成「accuracy」。
4) 只要指標中包含 F-score、F-measure、macroF、microF、F1,就把指標都歸一化為「F-measure」。
5) 如果詞組中的某個單詞全由大寫字母組成且該詞組最后一個單詞不是 rate、ratio、error,則只保留全由大寫字母組成的單詞。例如,「ACC information」歸一化成「ACC」,「RMS error」歸一化成「RMS error」。
6) 取詞組中每個單詞的首字母(如果該單詞全由大寫字母組成,則取該單詞的全部字母),查詢所有指標中是否存在唯一與之對應的單詞(即查找全稱對應的唯一縮寫)。若存在,則將縮寫與全稱都歸一化成「縮寫(全稱)」。














