如何在沉浸環境中真正感受到沉浸式體驗?那就是,在虛擬場景中,依然可以實現與現實世界中一樣的交互。例如,在體驗一款游戲時,你可以直接使用你在虛擬世界的“數字化分手”,自然地與同伴打招呼、握手、擊掌,還能完成各種抓取動作…..隨著計算機視覺、AI等技術對自然肢體語言的識別, 不再僅通過手柄定義你在虛擬世界中的動作,正在成為可能。
這種通過手勢識別打破次元壁,獲得更佳臨場感的方式,已成為當前VR、AR消費級頭顯設備重點研究的方向之一,但如果手部識別精度不夠,則可能無法做到對真實雙手姿態的完美復刻。為達到更好的效果,如何以更精準的方式同步還原人類雙手在物理世界的靈動姿態,完成比手柄控制更精細的操作,就顯得尤為重要。
近日,愛奇藝的深度學習云算法小組通過題為《I2UV-HandNet: Image-to-UV Prediction Network for Accurate and High-fidelity 3D Hand Mesh Modeling》(I2UV-HandNet:基于圖像到UV Map映射的3D手部高保真重建網絡)的論文再獲關注。
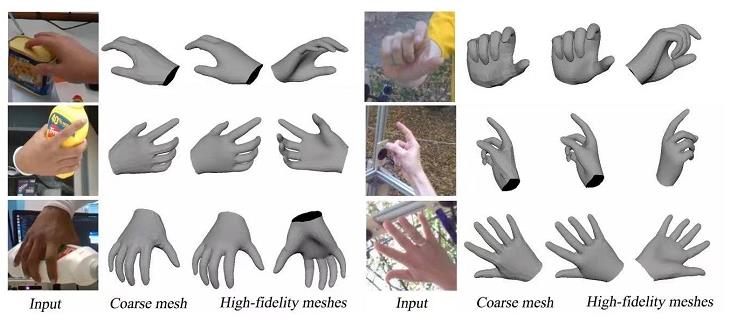
針對現有模型在手部姿態識別方面不夠精細等問題,該論文提出一套I2UV-HandNet高精度手部重建系統,并依托愛奇藝在業內首提的將點的超分轉化為圖像超分這一先進技術思考,能夠做到識別21個關節點和26自由度的手部運動信息,從而更有效地實現更高等級的手部還原。這將使得在VR、AR等使用場景下,用戶通過更精細的手勢追蹤與識別,更準確、流暢地完成更多操作,享受在虛擬世界更佳的臨場感。基于該系統的行業首創性和卓越應用價值,該篇論文成功被今年接收率僅為25.9%的國際計算機視覺大會(ICCV)成功收錄,并在業內頗受認可的HO3D以及Freihand 在線測評榜持續數月排名第一,超越目前的SOTA水平(若某篇論文能夠被稱為SOTA,就表明其提出的算法(模型)的性能在所在領域為最優)。
通常而言,要讓手勢識別實現更高的精度,首先需要好的手部模型,只有好的模型才能預測出來更多3D點。同時需要有足夠的高精度數據,才能不斷訓練重建模型。基于大量手部數據對深度學習算法的“喂養”,愛奇藝自研的I2UV-HandNet高精度手部重建系統,能夠通過UV重建模塊AffineNet,完成由粗到精的人手3D模型重建。這樣一來,即使在大遮擋或多姿態狀態下,該系統仍可有效改善現有人手模型識別不準確等問題,為手勢識別提供更為完整且精準的參考。
同時,考慮到不同虛擬場景對手部3D模型的精度要求不一,該系統還可通過SRNet網絡實現對已有人手3D模型更高精度的重建。該系統基于落實“點的超分轉化為圖像的超分”的先進技術思考,通過算法從低精度UV圖到高精度UV圖的學習,可完成MANO(778個點/1538個面)人手模型向高精度(3093個點/6152個面)乃至更精細(上萬點云)的人手模型的重建,這可以實現雙手的“虛擬分身”在不同背景色彩、景深下,表現得如物理世界雙手一樣靈活。
值得一提的是,未來該系統將應用于下一代奇遇VR中,賦能愛奇藝VR更佳的沉浸感,讓用戶不僅僅是瀏覽內容,更有機會“走進內容”。可以預見,該系統基于更低成本的深度學習算法完成的高精度手勢識別,相比通過自帶深度信息識別的攝像頭,將更具性價比和規模化落地的商業潛力,也將為愛奇藝更多業務場景或硬件終端增強“沉浸體驗”帶來更為強大助力。














