北京時間2022年3月21日晚23:00,NVIDIA 2022年GTC大會正式開啟。正如各家媒體預測的那樣,官方不但發了萬眾矚目的Hopper架構H100加速卡,還推出了專為AI及超算設計的CPU處理器Grace、AI計算系統“DGX H100”。

值得一提的是,Grace芯片擁有144個核心,內存帶寬達恐怖的1TB/s,而整體功耗僅為500W。作為GPU領域的龍頭企業,Nvidia表示Grace在性能方面完全碾壓業內所有對手。
厚積薄發的Grace
事實上,NVIDIA早在2021年就對外宣布了Grace芯片,但其詳細規格始終是個迷。今晚,官方終于宣布了它的詳細規格:兩個CPU芯片,一個叫做Grace Hopper,為CPU+GPU合體設計,它使用了Nvidia的最新NVLink技術連接,帶寬為900GB/s。

與之相較,另個一名為Grace CPU Superchip的芯片則更為強大,它的規格是兩個Grac CPU一起封裝,總共擁有144個基于ARMv9指令集的CPU內核,緩存容量396MB,支持LPDDR5X ECC內存,帶寬為1TB/s。另外,這款芯片還支持PCIe 5.0、NVLink-C2C互連。

在外界最關注的性能方面,Grace CPU Superchip的SPECint 2017得分為740分,暫時登上了業內最頂峰。

在首席執行官黃仁勛看來,在Grace Hopper及Grace CPU Superchip的加持下,NVIDIA在未來可以靈活搭配各種B端方案,就像是搭積木那樣簡單。

在宣布完規格后,老黃表示:Grace CPU Superchip芯片會在2023年上市。

專攻AI的Hopper
與傳聞不同,GH100核心采用的其實是臺積電目前最先進的4nm工藝,而且是定制版,CoWoS 2.5D晶圓級封裝,單芯片設計,集成多達800億個晶體管,號稱世界上最先進的芯片。

官方沒有公布核心數,但已經被挖掘出來,和此前傳聞一直。
完整版有8組GPC(圖形處理器集群)、72組TPC(紋理處理器集群)、144組SM(流式多處理器單元),而每組SM有128個FP32 CUDA核心,總計1843個。
顯存支持六顆HBM3或者HBM2e,控制器是12組512-bit,總計位寬6144-bit。
Tensor張量核心來到第四代,共有576個,另有60MB二級緩存。
擴展互連支持PCIe 5.0、NVLink第四代,后者帶寬提升至900GB/s,七倍于PCIe 5.0,相比A100也多了一半。整卡對外總帶寬4.9TB/s。
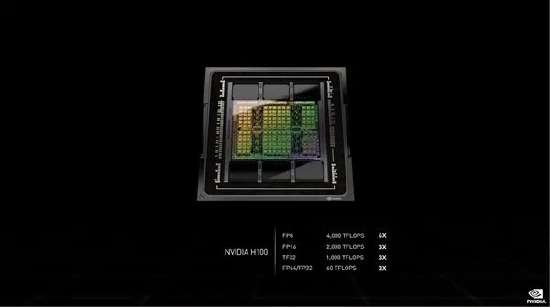
性能方面,FP64/FP32 60TFlops(每秒60萬億次),FP16 2000TFlops(每秒2000萬億次),TF32 1000TFlops(每秒1000萬億次),都三倍于A100,FP8 4000TFlops(每秒4000萬億次),六倍于A100。
H100計算卡采用SXM、PCIe 5.0兩種形態,其中后者功耗高達史無前例的700W,相比A100多了整整300W。
按慣例也不是滿血,GPC雖然還是8組,但只開啟了66組TPC(魅族GPC屏蔽一組TPC)、132組SM,總計有16896個CUDA核心、528個Tensor核心、50MB二級緩存。
顯存只用了五顆,最新一代HBM3,容量80GB,位寬5120-bit,帶寬高達3TB/s,相比A100多了一半。

史無前例的DGX H100
在擁有了強大的芯片基礎后,NVIDIA也擁有了強大的算力基礎,并以此推出了更加強大的AI運算系統:DGX H100。

據官方介紹,該系統集成了八顆H100芯片、搭配兩顆PCIe 5.0 CPU處理器(Intel Sapphire Rapids四代可擴展至器)。在規格方面,它總共有用6400億個晶體管、640GB HBM3顯存、24TB/s顯存帶寬。

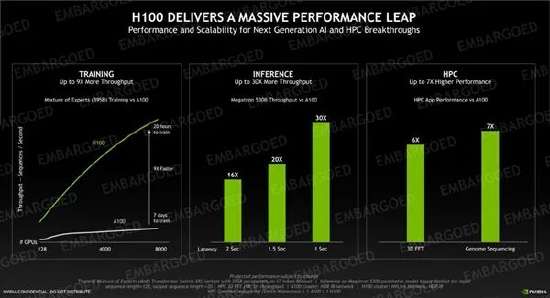
性能方面,DGX H100的AI算力為32PFlops(每秒3.2億億次),浮點算力FP64 480TFlops(每秒480萬億次),FP16 1.6PFlops(每秒1.6千萬億次),FP8 3.2PFlops(每秒3.2千億次),分別是上代DGX A100的3倍、3倍、6倍,而且新增支持網絡內計算,性能3.6TFlops。

同時,它還配備Connect TX-7網絡互連芯片,臺積電7nm工藝,800億個晶體管,400G GPUDirect吞吐量,400G加密加速,4.05億/秒信息率。
事實上,如此強大的DGX H100還只是最小的計算單元。為了擴展其應用規模,NVIDIA本次還設計了全新的VNLink Swtich互連系統,可以連接最多32個節點,也就是256顆H100芯片,稱之為“DGX POD”。

在這套擁有極致性能的系統內,NVIDIA為其塞入了20.5TB HBM3內存,總帶寬768TB/s,AI性能高達顛覆性的1EFlops(100億億億次每秒),實現百億億次計算。

據黃仁勛表示,目前DGX H100的合作伙伴包括Atos、思科、戴爾、富士通、技嘉、新華三、慧與、浪潮、聯想、寧暢、超威。

另外,該系統的云服務合作伙伴包括阿里云、亞馬遜云、百度云、Google云、微軟Azure、甲骨文云、騰訊云。

廣泛的應用領域
眾所周知,近幾年興起的人工智能浪潮,根本原因正是計算力的快速發展,結合互聯網、物聯網帶來的海量數據和深度學習等先進算法共同催生而成,其實際應用效果和社會影響力遠遠超出以往。
但是,隨著人工智能的快速發展,更深更大的算法模型、更復雜的架構正在成為趨勢。在這種情況之下,如果計算力不能相應增長,整個人工智能的學習過程將變得無比漫長。可以說,人工智能對計算的需求是永無止境的。

正式基于以上背景,我們也就不難理解NVIDIA在這機年中快速崛起的真正秘訣:正是因為其強大的GPU有效彌補了CPU的不足,并大大加速了處理高強度計算負載的能力,從而讓GPU計算的潛力得以全面的釋放。
在本次GTC大會上,NVIDIA不但推出了強大的運算芯片,還就AI領域的發展、以及該技術在科研、數字孿生、自動駕駛乃至金融等行業的深度應用作出了前瞻。

在我們看來,NVIDIA一系列圍繞人工智能領域的布局和創新,不僅是大勢所趨,更是這家芯片業巨頭在新時代的新使命。可以說,AI賦予了NVIDIA未來更大的想象力,而NVIDIA也正引領人工智能走向更大的舞臺。














